Ruby Hacking Guide
Chapter 13: Structure of the evaluator
Outline
Interface
We are not familiar with the word “Hyo-ka-ki” (evaluator). Literally, it must be a “-ki” (device) to “hyo-ka” (evaluating). Then, what is “hyo-ka”?
“Hyo-ka” is the definitive translation of “evaluate”. However, if the premise is describing about programing languages, it can be considered as an error in translation. It’s hard to avoid that the word “hyo-ka” gives the impression of “whether it is good or bad”.
“Evaluate” in the context of programing languages has nothing to do with “good or bad”, and its meaning is more close to “speculating” or “executing”. The origin of “evaluate” is a Latin word “ex+value+ate”. If I translate it directly, it is “turn it into a value”. This may be the simplest way to understand: to determine the value from an expression expressed in text.
Very frankly speaking, the bottom line is that evaluating is executing a written expression and getting the result of it. Then why is it not called just “execute”? It’s because evaluating is not only executing.
For example, in an ordinary programming language, when we write “3”,
it will be dealt with as an integer 3.
This situation is sometimes described as “the result of evaluating
”3" is 3". It’s hard to say an expression of a constant is executed,
but it is certainly an evaluation.
It’s all right if there exist a programming language in which the letter “3”,
when it is evaluated, will be dealt with (evaluated) as an integer 6.
I’ll introduce another example. When an expression consists of multiple constants, sometimes the constants are calculated during the compiling process (constant folding). We usually don’t call it “executing” because executing indicates the process that the created binary is working. However, no matter when it is calculated you’ll get the same result from the same program.
In other words, “evaluating” is usually equals to “executing”, but essentially “evaluating” is different from “executing”. For now, only this point is what I’d like you to remember.
The characteristics of ruby's evaluator.
The biggest characteristic of `ruby`‘s evaluator is that, as this is also of
the whole `ruby`’s interpretor, the difference in expressions between
the C-level code (extension libraries) and the Ruby-level code is small.
In ordinary programming languages,
the amount of the features of its interpretor we can use from extension
libraries is usually very limited, but there are awfully few limits in ruby.
Defining classes, defining methods and calling a method without limitation,
these can be taken for granted. We can also use exception handling, iterators.
Furthermore, threads.
But we have to compensate for the conveniences somewhere. Some codes are weirdly hard to implement, some codes have a lot overhead, and there are a lot of places implementing the almost same thing twice both for C and Ruby.
Additionally, ruby is a dynamic language,
it means that you can construct and evaluate a string at runtime.
That is eval which is a function-like method. As you expected,
it is named after “evaluate”. By using it, you can even do something like this:
lvar = 1
answer = eval("lvar + lvar") # the answer is 2
There are also Module#module_eval and Object#instance_eval, each method
behaves slightly differently. I’ll describe about them in detail in Chapter 17: Dynamic evaluation.
eval.c
The evaluator is implemented in eval.c. However, this eval.c is a
really huge file: it has 9000 lines, its size is 200K bytes,
and the number of the functions in it is 309. It is hard to fight against.
When the size becomes this amount,
it’s impossible to figure out its structure by just looking over it.
So how can we do? First, the bigger the file, the less possibility of its content not separated at all. In other words, the inside of it must be modularized into small portions. Then, how can we find the modules? I’ll list up some ways.
The first way is to print the list of the defined functions and look at the
prefixes of them. rb_dvar_, rb_mod_, rb_thread — there are plenty of
functions with these prefixes.
Each prefix clearly indicate a group of the same type of functions.
Alternatively, as we can tell when looking at the code of the class libraries,
Init_xxxx() is always put at the end of a block in ruby.
Therefore, Init_xxxx() also indicates a break between modules.
Additionally, the names are obviously important, too.
Since eval() and rb_eval() and eval_node() appear close to each other,
we naturally think there should be a deep relationship among them.
Finally, in the source code of ruby, the definitions of types or variables
and the declarations of prototypes often indicate a break between modules.
Being aware of these points when looking,
it seems that eval.c can be mainly divided into these modules listed below:
| Safe Level | already explained in Chapter 7: Security |
| Method Entry Manipulations | finding or deleting syntax trees which are actual method bodies |
| Evaluator Core | the heart of the evaluator that rb_eval() is at its center. |
| Exception | generations of exceptions and creations of backtraces |
| Method | the implementation of method call |
| Iterator | the implementation of functions that are related to blocks |
| Load | loading and evaluating external files |
Proc |
the implementation of Proc |
| Thread | the implementation of Ruby threads |
Among them, “Load” and “Thread” are the parts that essentially should not be in eval.c.
They are in eval.c merely because of the restrictions of C language.
To put it more precisely, they need the macros such as PUSH_TAG defined in eval.c.
So, I decided to exclude the two topics from Part 3 and deal with them
at Part 4. And, it’s probably all right if I don’t explain the safe level here
because I’ve already done in Part 1.
Excluding the above three, the six items are left to be described. The below table shows the corresponding chapter of each of them:
| Method Entry Manipulations | the next chapter: Context |
| Evaluator Core | the entire part of Part 3 |
| Exception | this chapter |
| Method | Chapter 15: Methods |
| Iterator | Chapter 16: Blocks |
| Proc | Chapter 16: Blocks |
From main by way of ruby_run to rb_eval
Call Graph
The true core of the evaluator is a function called rb_eval().
In this chapter, we will follow the path from main() to that rb_eval().
First of all, here is a rough call graph around rb_eval :
main ....main.c
ruby_init ....eval.c
ruby_prog_init ....ruby.c
ruby_options ....eval.c
ruby_process_options ....ruby.c
ruby_run ....eval.c
eval_node
rb_eval
*
ruby_stop
I put the file names on the right side when moving to another file.
Gazing this carefully, the first thing we’ll notice is that the functions of
eval.c call the functions of ruby.c back.
I wrote it as “calling back” because main.c and ruby.c are relatively for
the implementation of ruby command. eval.c is the implementation of the
evaluator itself which keeps a little distance from ruby command.
In other words, eval.c is supposed to be used by ruby.c and calling the
functions of ruby.c from eval.c makes eval.c less independent.
Then, why is this in this way? It’s mainly because of the restrictions of C language.
Because the functions such as ruby_prog_init() and ruby_process_options()
start to use the API of the ruby world, it’s possible an exception occurs.
However, in order to stop an exception of Ruby, it’s necessary to use the macro
named PUSH_TAG() which can only be used in eval.c. In other words, essentially,
ruby_init() and ruby_run() should have been defined in ruby.c.
Then, why isn’t PUSH_TAG an extern function or something which is available
to other files?
Actually, PUSH_TAG can only be used as a pair with POP_TAG as follows:
PUSH_TAG(); /* do lots of things */ POP_TAG();
Because of its implementation, the two macros should be put into the same function. It’s possible to implement in a way to be able to divide them into different functions, but not in such way because it’s slower.
The next thing we notice is, the fact that it sequentially calls the functions
named ruby_xxxx from main() seems very meaningful.
Since they are really obviously symmetric, it’s odd if there’s not any relationship.
Actually, these three functions have deep relationships. Simply speaking, all of
these three are “built-in Ruby interfaces”. That is, they are used only when
creating a command with built-in ruby interpretor and not when writing
extension libraries. Since ruby command itself can be considered as one of
programs with built-in Ruby in theory, to use these interfaces is natural.
What is the ruby_ prefix ? So far, the all of ruby ’s functions are prefixed
with rb_. Why are there the two types: rb_ and ruby_? I investigated but
could not understand the difference, so I asked directly. The answer was,
“ruby_ is for the auxiliary functions of ruby command and rb_ is for the
official interfaces”
“Then, why are the variables like ruby_scope are ruby_?”, I asked further.
It seems this is just a coincidence. The variables like ruby_scope
are originally named as the_xxxx, but in the middle of the version 1.3 there’s
a change to add prefixes to all interfaces. At that time ruby_ was added to
the “may-be-internals-for-some-reasons” variables.
The bottom line is that ruby_ is attached to things that support
ruby command or the internal variables and rb_ is attached to
the official interfaces of ruby interpretor.
main()
First, straightforwardly, I’ll start with main().
It is nice that this is very short.
▼ main()
36 int
37 main(argc, argv, envp)
38 int argc;
39 char **argv, **envp;
40 {
41 #if defined(NT)
42 NtInitialize(&argc, &argv);
43 #endif
44 #if defined(__MACOS__) && defined(__MWERKS__)
45 argc = ccommand(&argv);
46 #endif
47
48 ruby_init();
49 ruby_options(argc, argv);
50 ruby_run();
51 return 0;
52 }
(main.c)
#if def NT is obviously the NT of Windows NT. But somehow NT is also
defined in Win9x. So, it means Win32 environment.
NtInitialize() initializes argc argv and the socket system (WinSock) for
Win32. Because this function is only doing the initialization, it’s not
interesting and not related to the main topic. Thus, I omit this.
And, __MACOS__ is not “Ma-Ko-Su” but Mac OS. In this case, it means
Mac OS 9 and before, and it does not include Mac OS X. Even though such
#ifdef remains, as I wrote at the beginning of this book, the current version
can not run on Mac OS 9 and before. It’s just a legacy from when ruby was
able to run on it. Therefore, I also omit this code.
By the way, as it is probably known by the readers who are familiar with C language,
the identifiers starting with an under bar are reserved for the system libraries or OS.
However, although they are called “reserved”, using it is almost never result in an error,
but if using a little weird cc it could result in an error.
For example, it is the cc of HP-US. HP-US is an UNIX which HP is creating.
If there’s any opinion such as HP-UX is not weird, I would deny it out loud.
Anyway, conventionally, we don’t define such identifiers in user applications.
Now, I’ll start to briefly explain about the built-in Ruby interfaces.
ruby_init()
ruby_init() initializes the Ruby interpretor.
Since only a single interpretor of the current Ruby can exist in a process,
it does not need neither arguments or a return value.
This point is generally considered as “lack of features”.
When there’s only a single interpretor,
more than anything,
things around the development environment should be especially troublesome.
Namely, the applications such as irb, RubyWin, and RDE.
Although loading a rewritten program, the classes which are supposed to be
deleted would remain. To counter this with the reflection API is not impossible
but requires a lot of efforts.
However, it seems that Mr. Matsumoto (Matz) purposefully limits the number of interpretors to one. “it’s impossible to initialize completely” seems its reason. For instance, “the loaded extension libraries could not be removed” is taken as an example.
The code of ruby_init() is omitted because it’s unnecessary to read.
ruby_options()
What to parse command-line options for the Ruby interpreter is ruby_options().
Of course, depending on the command, we do not have to use this.
Inside this function, -r (load a library) and
-e (pass a program from command-line) are processed.
This is also where the file passed as a command-line argument is parsed as
a Ruby program.
ruby command reads the main program from a file if it was given, otherwise from stdin.
After that, using rb_compile_string() or rb_compile_file() introduced at Part 2,
it compiles the text into a syntax tree.
The result will be set into the global variable ruby_eval_tree.
I also omit the code of ruby_options() because it’s just doing necessary
things one by one and not interesting.
ruby_run()
Finally, ruby_run() starts to evaluate the syntax tree which was set to ruby_eval_tree.
We also don’t always need to call this function. Other than ruby_run(),
for instance, we can evaluate a string by using a function named rb_eval_string().
▼ ruby_run()
1257 void
1258 ruby_run()
1259 {
1260 int state;
1261 static int ex;
1262 volatile NODE *tmp;
1263
1264 if (ruby_nerrs > 0) exit(ruby_nerrs);
1265
1266 Init_stack((void*)&tmp);
1267 PUSH_TAG(PROT_NONE);
1268 PUSH_ITER(ITER_NOT);
1269 if ((state = EXEC_TAG()) == 0) {
1270 eval_node(ruby_top_self, ruby_eval_tree);
1271 }
1272 POP_ITER();
1273 POP_TAG();
1274
1275 if (state && !ex) ex = state;
1276 ruby_stop(ex);
1277 }
(eval.c)
We can see the macros PUSH_xxxx(), but we can ignore them for now. I’ll
explain about around them later when the time comes. The important thing here
is only eval_node(). Its content is:
▼ eval_node()
1112 static VALUE
1113 eval_node(self, node)
1114 VALUE self;
1115 NODE *node;
1116 {
1117 NODE *beg_tree = ruby_eval_tree_begin;
1118
1119 ruby_eval_tree_begin = 0;
1120 if (beg_tree) {
1121 rb_eval(self, beg_tree);
1122 }
1123
1124 if (!node) return Qnil;
1125 return rb_eval(self, node);
1126 }
(eval.c)
This calls rb_eval() on ruby_eval_tree. The ruby_eval_tree_begin is
storing the statements registered by BEGIN. But, this is also not important.
And, ruby_stop() inside of ruby_run() terminates all threads and
finalizes all objects and checks exceptions and, in the end, calls exit().
This is also not important, so we won’t see this.
rb_eval()
Outline
Now, rb_eval(). This function is exactly the real core of ruby.
One rb_eval() call processes a single NODE, and the whole syntax tree will
be processed by calling recursively. (Fig.1)
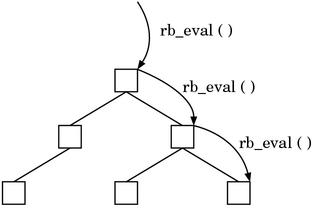
Fig.1: rb_eval
rb_eval is, as the same as yylex(), made of a huge switch statement and
branching by each type of the nodes. First, let’s look at the outline.
▼ rb_eval() Outline
2221 static VALUE
2222 rb_eval(self, n)
2223 VALUE self;
2224 NODE *n;
2225 {
2226 NODE *nodesave = ruby_current_node;
2227 NODE * volatile node = n;
2228 int state;
2229 volatile VALUE result = Qnil;
2230
2231 #define RETURN(v) do { \
2232 result = (v); \
2233 goto finish; \
2234 } while (0)
2235
2236 again:
2237 if (!node) RETURN(Qnil);
2238
2239 ruby_last_node = ruby_current_node = node;
2240 switch (nd_type(node)) {
case NODE_BLOCK:
.....
case NODE_POSTEXE:
.....
case NODE_BEGIN:
:
(plenty of case statements)
:
3415 default:
3416 rb_bug("unknown node type %d", nd_type(node));
3417 }
3418 finish:
3419 CHECK_INTS;
3420 ruby_current_node = nodesave;
3421 return result;
3422 }
(eval.c)
In the omitted part, plenty of the codes to process all nodes are listed.
By branching like this, it processes each node. When the code is only a few,
it will be processed in rb_eval(). But when it becoming many, it will be a
separated function. Most of functions in eval.c are created in this way.
When returning a value from rb_eval(), it uses the macro RETURN() instead
of return, in order to always pass through CHECK_INTS. Since this macro is
related to threads, you can ignore this until the chapter about it.
And finally, the local variables result and node are volatile for GC.
NODE_IF
Now, taking the if statement as an example, let’s look at the process of
the rb_eval() evaluation concretely.
From here, in the description of rb_eval(),
- The source code (a Ruby program)
- Its corresponding syntax tree
- The partial code of
rb_eval()to process the node.
these three will be listed at the beginning.
▼source program
if true 'true expr' else 'false expr' end
▼ its corresponding syntax tree ( nodedump )
NODE_NEWLINE
nd_file = "if"
nd_nth = 1
nd_next:
NODE_IF
nd_cond:
NODE_TRUE
nd_body:
NODE_NEWLINE
nd_file = "if"
nd_nth = 2
nd_next:
NODE_STR
nd_lit = "true expr":String
nd_else:
NODE_NEWLINE
nd_file = "if"
nd_nth = 4
nd_next:
NODE_STR
nd_lit = "false expr":String
As we’ve seen in Part 2, elsif and unless can be, by contriving the ways to assemble,
bundled to a single NODE_IF type, so we don’t have to treat them specially.
▼ rb_eval() − NODE_IF
2324 case NODE_IF:
2325 if (trace_func) {
2326 call_trace_func("line", node, self,
2327 ruby_frame->last_func,
2328 ruby_frame->last_class);
2329 }
2330 if (RTEST(rb_eval(self, node->nd_cond))) {
2331 node = node->nd_body;
2332 }
2333 else {
2334 node = node->nd_else;
2335 }
2336 goto again;
(eval.c)
Only the last if statement is important.
If rewriting it without any change in its meaning, it becomes this:
if (RTEST(rb_eval(self, node->nd_cond))) { (A)
RETURN(rb_eval(self, node->nd_body)); (B)
}
else {
RETURN(rb_eval(self, node->nd_else)); (C)
}
First, at (A), evaluating (the node of) the Ruby’s condition statement and
testing its value with RTEST().
I’ve mentioned that RTEST() is a macro to test whether or not
a VALUE is true of Ruby.
If that was true, evaluating the then side clause at (B).
If false, evaluating the else side clause at (C).
In addition, I’ve mentioned that if statement of Ruby also has its own value,
so it’s necessary to return a value.
Since the value of an if is the value of either the then side or the else
side which is the one executed, returning it by using the macro RETURN().
In the original list, it does not call rb_eval() recursively but just does goto.
This is the "conversion from tail recursion to goto " which has also appeared
in the previous chapter “Syntax tree construction”.
NODE_NEW_LINE
Since there was NODE_NEWLINE at the node for a if statement,
let’s look at the code for it.
▼ rb_eval() – NODE_NEWLINE
3404 case NODE_NEWLINE:
3405 ruby_sourcefile = node->nd_file;
3406 ruby_sourceline = node->nd_nth;
3407 if (trace_func) {
3408 call_trace_func("line", node, self,
3409 ruby_frame->last_func,
3410 ruby_frame->last_class);
3411 }
3412 node = node->nd_next;
3413 goto again;
(eval.c)
There’s nothing particularly difficult.
call_trace_func() has already appeared at NODE_IF. Here is a simple
explanation of what kind of thing it is. This is a feature to trace a Ruby
program from Ruby level. The debugger ( debug.rb ) and the tracer ( tracer.rb )
and the profiler ( profile.rb ) and irb (interactive ruby command) and more
are using this feature.
By using the function-like method set_trace_func you can register a Proc
object to trace, and that Proc object is stored into trace_func. If
trace_func is not 0, it means not QFalse, it will be considered as a Proc
object and executed (at call_trace_func() ).
This call_trace_func() has nothing to do with the main topic and not so
interesting as well. Therefore in this book, from now on,
I’ll completely ignore it. If you are interested in it, I’d like you to
challenge after finishing the Chapter 16: Blocks.
Pseudo-local Variables
NODE_IF and such are interior nodes in a syntax tree.
Let’s look at the leaves, too.
▼ rb_eval() Ppseudo-Local Variable Nodes
2312 case NODE_SELF: 2313 RETURN(self); 2314 2315 case NODE_NIL: 2316 RETURN(Qnil); 2317 2318 case NODE_TRUE: 2319 RETURN(Qtrue); 2320 2321 case NODE_FALSE: 2322 RETURN(Qfalse); (eval.c)
We’ve seen self as the argument of rb_eval(). I’d like you to make sure it
by going back a little.
The others are probably not needed to be explained.
Jump Tag
Next, I’d like to explain NODE_WHILE which is corresponding to while,
but to implement break or next only with recursive calls of a function is difficult.
Since ruby enables these syntaxes by using what named “jump tag”,
I’ll start with describing it first.
Simply put, “jump tag” is a wrapper of setjmp() and longjump() which are
library functions of C language. Do you know about setjmp()?
This function has already appeared at gc.c,
but it is used in very abnormal way there.
setjmp() is usually used to jump over functions.
I’ll explain by taking the below code as an example.
The entry point is parent().
▼ setjmp() and longjmp()
jmp_buf buf;
void child2(void) {
longjmp(buf, 34); /* go back straight to parent
the return value of setjmp becomes 34 */
puts("This message will never be printed.");
}
void child1(void) {
child2();
puts("This message will never be printed.");
}
void parent(void) {
int result;
if ((result = setjmp(buf)) == 0) {
/* normally returned from setjmp */
child1();
} else {
/* returned from child2 via longjmp */
printf("%d\n", result); /* shows 34 */
}
}
First, when setjmp() is called at parent(),
the executing state at the time is saved to the argument buf.
To put it a little more directly, the address of the top of the machine
stack and the CPU registers are saved.
If the return value of setjmp() was 0, it means it normally returned from setjmp(),
thus you can write the subsequent code as usual.
This is the if side. Here, it calls child1().
Next, the control moves to child2() and calls longjump,
then it can go back straight to the place where the argument buf was setjmp ed.
So in this case, it goes back to the setjmp at parent().
When coming back via longjmp, the return value of setjmp becomes
the value of the second argument of longjmp, so the else side is executed.
And, even if we pass 0 to longjmp,
it will be forced to be another value. Thus it’s fruitless.
Fig.2 shows the state of the machine stack.
The ordinary functions return only once for each call.
However, it’s possible setjmp() returns twice.
Is it helpful to grasp the concept if I say that it is something like fork()?
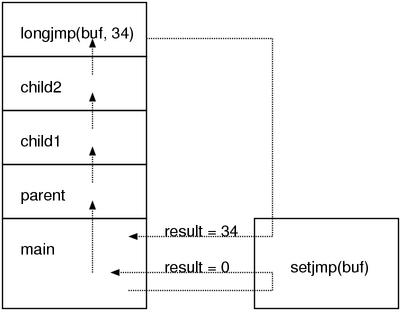
Fig.2: setjmp() longjmp() Image
Now, we’ve learned about setjmp() as a preparation.
In eval.c, EXEC_TAG corresponds to setjmp() and JUMP_TAG() corresponds
to longjmp() respectively. (Fig.3)
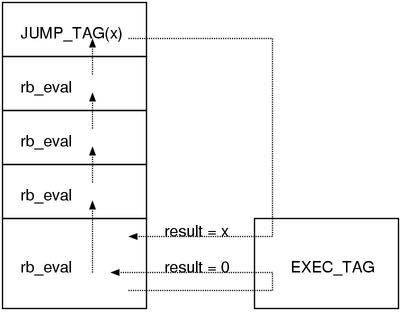
Fig.3: “tag jump” image
Take a look at this image, it seems that EXEC_TAG() does not have any arguments.
Where has jmp_buf gone?
Actually, in ruby, jmp_buf is wrapped by the struct struct tag.
Let’s look at it.
▼ struct tag
783 struct tag {
784 jmp_buf buf;
785 struct FRAME *frame; /* FRAME when PUSH_TAG */
786 struct iter *iter; /* ITER when PUSH_TAG */
787 ID tag; /* tag type */
788 VALUE retval; /* the return value of this jump */
789 struct SCOPE *scope; /* SCOPE when PUSH_TAG */
790 int dst; /* the destination ID */
791 struct tag *prev;
792 };
(eval.c)
Because there’s the member prev, we can infer that struct tag is probably
a stack structure using a linked list. Moreover, by looking around it, we can
find the macros PUSH_TAG() and POP_TAG, thus it definitely seems a stack.
▼ PUSH_TAG() POP_TAG()
793 static struct tag *prot_tag; /* the pointer to the head of the machine stack */
795 #define PUSH_TAG(ptag) do { \
796 struct tag _tag; \
797 _tag.retval = Qnil; \
798 _tag.frame = ruby_frame; \
799 _tag.iter = ruby_iter; \
800 _tag.prev = prot_tag; \
801 _tag.scope = ruby_scope; \
802 _tag.tag = ptag; \
803 _tag.dst = 0; \
804 prot_tag = &_tag
818 #define POP_TAG() \
819 if (_tag.prev) \
820 _tag.prev->retval = _tag.retval;\
821 prot_tag = _tag.prev; \
822 } while (0)
(eval.c)
I’d like you to be flabbergasted here because the actual tag is fully allocated
at the machine stack as a local variable. (Fig.4). Moreover, do ~ while is
divided between the two macros.
This might be one of the most awful usages of the C preprocessor.
Here is the macros PUSH / POP coupled and extracted to make it easy to read.
do {
struct tag _tag;
_tag.prev = prot_tag; /* save the previous tag */
prot_tag = &_tag; /* push a new tag on the stack */
/* do several things */
prot_tag = _tag.prev; /* restore the previous tag */
} while (0);
This method does not have any overhead of function calls,
and its cost of the memory allocation is next to nothing.
This technique is only possible because the ruby evaluator is made of
recursive calls of rb_eval().
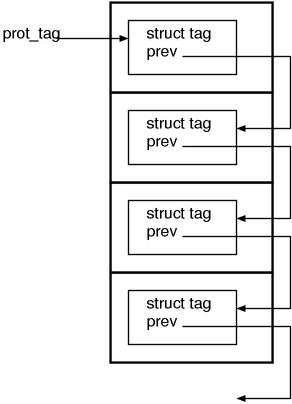
Fig.4: the tag stack is embedded in the machine stack
Because of this implementation, it’s necessary that PUSH_TAG and POP_TAG
are in the same one function as a pair. Plus, since it’s not supposed to be
carelessly used at the outside of the evaluator,
we can’t make them available to other files.
Additionally, let’s also take a look at EXEC_TAG() and JUMP_TAG().
▼ EXEC_TAG() JUMP_TAG()
810 #define EXEC_TAG() setjmp(prot_tag->buf)
812 #define JUMP_TAG(st) do { \
813 ruby_frame = prot_tag->frame; \
814 ruby_iter = prot_tag->iter; \
815 longjmp(prot_tag->buf,(st)); \
816 } while (0)
(eval.c)
In this way, setjmp and longjmp are wrapped by EXEC_TAG() and JUMP_TAG() respectively.
The name EXEC_TAG() can look like a wrapper of longjmp() at first sight,
but this one is to execute setjmp().
Based on all of the above, I’ll explain the mechanism of while.
First, when starting while it does EXEC_TAG() ( setjmp ).
After that, it executes the main body by calling rb_eval()
recursively. If there’s break or next, it does JUMP_TAG() ( longjmp ).
Then, it can go back to the start point of the while loop. (Fig.5)
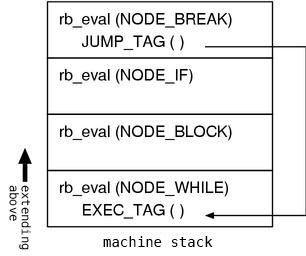
Fig.5: the implementation of while by using “tag jump”
Though break was taken as an example here, what cannot be implemented without
jumping is not only break. Even if we limit the case to while,
there are next and redo.
Additionally, return from a method and exceptions also should have to
climb over the wall of rb_eval().
And since it’s cumbersome to use a different tag stack for each case,
we want for only one stack to handle all cases in one way or another.
What we need to make it possible is just attaching information about
“what the purpose of this jump is”.
Conveniently, the return value of setjmp() could be specified as the argument
of longjmp(), thus we can use this. The types are expressed by the following flags:
▼tag type
828 #define TAG_RETURN 0x1 /* return */ 829 #define TAG_BREAK 0x2 /* break */ 830 #define TAG_NEXT 0x3 /* next */ 831 #define TAG_RETRY 0x4 /* retry */ 832 #define TAG_REDO 0x5 /* redo */ 833 #define TAG_RAISE 0x6 /* general exceptions */ 834 #define TAG_THROW 0x7 /* throw(won't be explained in this boook)*/ 835 #define TAG_FATAL 0x8 /* fatal : exceptions which are not catchable */ 836 #define TAG_MASK 0xf (eval.c)
The meanings are written as each comment. The last TAG_MASK is the bitmask to
take out these flags from a return value of setjmp(). This is because the
return value of setjmp() can also include information which is not about a
“type of jump”.
NODE_WHILE
Now, by examining the code of NODE_WHILE, let’s check the actual usage of tags.
▼ The Source Program
while true 'true_expr' end
▼ Its corresponding syntax tree( nodedump-short )
NODE_WHILE
nd_state = 1 (while)
nd_cond:
NODE_TRUE
nd_body:
NODE_STR
nd_lit = "true_expr":String
▼ rb_eval – NODE_WHILE
2418 case NODE_WHILE:
2419 PUSH_TAG(PROT_NONE);
2420 result = Qnil;
2421 switch (state = EXEC_TAG()) {
2422 case 0:
2423 if (node->nd_state && !RTEST(rb_eval(self, node->nd_cond)))
2424 goto while_out;
2425 do {
2426 while_redo:
2427 rb_eval(self, node->nd_body);
2428 while_next:
2429 ;
2430 } while (RTEST(rb_eval(self, node->nd_cond)));
2431 break;
2432
2433 case TAG_REDO:
2434 state = 0;
2435 goto while_redo;
2436 case TAG_NEXT:
2437 state = 0;
2438 goto while_next;
2439 case TAG_BREAK:
2440 state = 0;
2441 result = prot_tag->retval;
2442 default:
2443 break;
2444 }
2445 while_out:
2446 POP_TAG();
2447 if (state) JUMP_TAG(state);
2448 RETURN(result);
(eval.c)
The idiom which will appear over and over again appeared in the above code.
PUSH_TAG(PROT_NONE);
switch (state = EXEC_TAG()) {
case 0:
/* process normally */
break;
case TAG_a:
state = 0; /* clear state because the jump waited for comes */
/* do the process of when jumped with TAG_a */
break;
case TAG_b:
state = 0; /* clear state because the jump waited for comes */
/* do the process of when jumped with TAG_b */
break;
default
break; /* this jump is not waited for, then ... */
}
POP_TAG();
if (state) JUMP_TAG(state); /* .. jump again here */
First, as PUSH_TAG() and POP_TAG() are the previously described mechanism,
it’s necessary to be used always as a pair. Also, they need to be written
outside of EXEC_TAG(). And, apply EXEC_TAG() to the just pushed jmp_buf.
This means doing setjmp().
If the return value is 0, since it means immediately returning from setjmp(),
it does the normal processing (this usually contains rb_eval() ).
If the return value of EXEC_TAG() is not 0, since it means returning via longjmp(),
it filters only the own necessary jumps by using case and
lets the rest ( default ) pass.
It might be helpful to see also the code of the jumping side.
The below code is the handler of the node of redo.
▼ rb_eval() – NODE_REDO
2560 case NODE_REDO: 2561 CHECK_INTS; 2562 JUMP_TAG(TAG_REDO); 2563 break; (eval.c)
As a result of jumping via JUMP_TAG(), it goes back to the last EXEC_TAG().
The return value at the time is the argument TAG_REDO. Being aware of this,
I’d like you to look at the code of NODE_WHILE and check what route is taken.
The idiom has enough explained, now I’ll explain about the code of NODE_WHILE
a little more in detail. As mentioned, since the inside of case 0: is the main
process, I extracted only that part.
Additionally, I moved some labels to enhance readability.
if (node->nd_state && !RTEST(rb_eval(self, node->nd_cond)))
goto while_out;
do {
rb_eval(self, node->nd_body);
} while (RTEST(rb_eval(self, node->nd_cond)));
while_out:
There are the two places calling rb_eval() on node->nd_state which
corresponds to the conditional statement. It seems that only the first test of
the condition is separated. This is to deal with both do ~ while and while
at once. When node->nd_state is 0 it is a do ~ while, when 1 it is an
ordinary while. The rest might be understood by following step-by-step,
I won’t particularly explain.
By the way, I feel like it easily becomes an infinite loop if there is next
or redo in the condition statement. Since it is of course exactly what the
code means, it’s the fault of who wrote it, but I’m a little curious about it.
So, I’ve actually tried it.
% ruby -e 'while next do nil end' -e:1: void value expression
It’s simply rejected at the time of parsing.
It’s safe but not an interesting result.
What produces this error is value_expr() of parse.y.
The value of an evaluation of while
while had not had its value for a long time, but it has been able to return
a value by using break since ruby 1.7.
This time, let’s focus on the flow of the value of an evaluation.
Keeping in mind that the value of the local variable result becomes the
return value of rb_eval(), I’d like you to look at the following code:
result = Qnil;
switch (state = EXEC_TAG()) {
case 0:
/* the main process */
case TAG_REDO:
case TAG_NEXT:
/* each jump */
case TAG_BREAK:
state = 0;
result = prot_tag->retval; (A)
default:
break;
}
RETURN(result);
What we should focus on is only (A). The return value of the jump seems to be
passed via prot_tag->retval which is a struct tag.
Here is the passing side:
▼ rb_eval() – NODE_BREAK
2219 #define return_value(v) prot_tag->retval = (v)
2539 case NODE_BREAK:
2540 if (node->nd_stts) {
2541 return_value(avalue_to_svalue(rb_eval(self, node->nd_stts)));
2542 }
2543 else {
2544 return_value(Qnil);
2545 }
2546 JUMP_TAG(TAG_BREAK);
2547 break;
(eval.c)
In this way, by using the macro return_value(), it assigns the value to the
struct of the top of the tag stack.
The basic flow is this, but in practice there could be another EXEC_TAG
between EXEC_TAG() of NODE_WHILE and JUMP_TAG() of NODE_BREAK.
For example, rescue of an exception handling can exist between them.
while cond # EXEC_TAG() for NODE_WHILE
begin # EXEC_TAG() again for rescue
break 1
rescue
end
end
Therefore, it’s hard to determine whether or not the strict tag of when doing
JUMP_TAG() at NODE_BREAK is the one which was pushed at NODE_WHILE.
In this case, because retval is propagated in POP_TAG() as shown below,
the return value can be passed to the next tag without particular thought.
▼ POP_TAG()
818 #define POP_TAG() \ 819 if (_tag.prev) \ 820 _tag.prev->retval = _tag.retval;\ 821 prot_tag = _tag.prev; \ 822 } while (0) (eval.c)
This can probably be depicted as Fig.6.
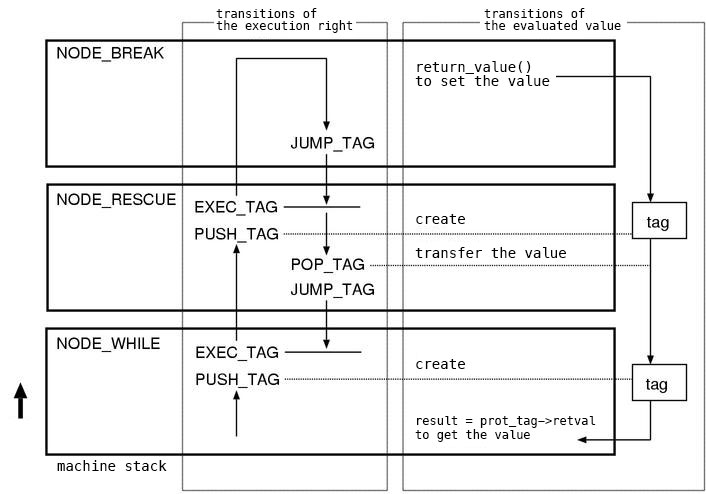
Fig.6: Transferring the return value
Exception
As the second example of the usage of “tag jump”, we’ll look at how exceptions are dealt with.
raise
When I explained while, we looked at the setjmp() side first. This time,
we’ll look at the longjmp() side first for a change. It’s rb_exc_raise()
which is the substance of raise.
▼ rb_exc_raise()
3645 void
3646 rb_exc_raise(mesg)
3647 VALUE mesg;
3648 {
3649 rb_longjmp(TAG_RAISE, mesg);
3650 }
(eval.c)
mesg is an exception object (an instance of Exception or one of its subclass).
Notice that It seems to jump with TAG_RAISE this time.
And the below code is very simplified rb_longjmp().
▼ rb_longjmp() (simplified)
static void
rb_longjmp(tag, mesg)
int tag;
VALUE mesg;
{
if (NIL_P(mesg))
mesg = ruby_errinfo;
set_backtrace(mesg, get_backtrace(mesg));
ruby_errinfo = mesg;
JUMP_TAG(tag);
}
Well, though this can be considered as a matter of course, this is just to jump
as usual by using JUMP_TAG().
What is ruby_errinfo? By doing grep a few times, I figured out that this
variable is the substance of the global variable $! of Ruby.
Since this variable indicates the exception which is currently occurring,
naturally its substance ruby_errinfo should have the same meaning as well.
The Big Picture
▼the source program
begin
raise('exception raised')
rescue
'rescue clause'
ensure
'ensure clause'
end
▼the syntax tree( nodedump-short )
NODE_BEGIN
nd_body:
NODE_ENSURE
nd_head:
NODE_RESCUE
nd_head:
NODE_FCALL
nd_mid = 3857 (raise)
nd_args:
NODE_ARRAY [
0:
NODE_STR
nd_lit = "exception raised":String
]
nd_resq:
NODE_RESBODY
nd_args = (null)
nd_body:
NODE_STR
nd_lit = "rescue clause":String
nd_head = (null)
nd_else = (null)
nd_ensr:
NODE_STR
nd_lit = "ensure clause":String
As the right order of rescue and ensure is decided at parser level,
the right order is
strictly decided at syntax tree as well. NODE_ENSURE is always at the “top”,
NODE_RESCUE comes next, the main body (where raise exist) is the last.
Since NODE_BEGIN is a node to do nothing, you can consider NODE_ENSURE is
virtually on the top.
This means, since NODE_ENSURE and NODE_RESCUE are above the main body which
we want to protect, we can stop raise by merely doing EXEC_TAG(). Or rather,
the two nodes are put above in syntax tree for this purpose, is probably more
accurate to say.
ensure
We are going to look at the handler of NODE_ENSURE which is the node of ensure.
▼ rb_eval() – NODE_ENSURE
2634 case NODE_ENSURE:
2635 PUSH_TAG(PROT_NONE);
2636 if ((state = EXEC_TAG()) == 0) {
2637 result = rb_eval(self, node->nd_head); (A-1)
2638 }
2639 POP_TAG();
2640 if (node->nd_ensr) {
2641 VALUE retval = prot_tag->retval; (B-1)
2642 VALUE errinfo = ruby_errinfo;
2643
2644 rb_eval(self, node->nd_ensr); (A-2)
2645 return_value(retval); (B-2)
2646 ruby_errinfo = errinfo;
2647 }
2648 if (state) JUMP_TAG(state); (B-3)
2649 break;
(eval.c)
This branch using if is another idiom to deal with tag.
It interrupts a jump by doing EXEC_TAG() then evaluates the ensure clause (
( node->nd_ensr ). As for the flow of the process, it’s probably straightforward.
Again, we’ll try to think about the value of an evaluation. To check the specification first,
begin expr0 ensure expr1 end
for the above statement, the value of the whole begin will be the value of
expr0 regardless of whether or not ensure exists.
This behavior is reflected to the code (A-1,2),
so the value of the evaluation of an ensure clause is completely discarded.
At (B-1,3), it deals with the evaluated value of when a jump occurred at the main body.
I mentioned that the value of this case is stored in prot_tag->retval,
so it saves the value to a local variable to prevent from being carelessly
overwritten during the execution of the ensure clause (B-1).
After the evaluation of the ensure clause, it restores the value by using
return_value() (B-2).
When any jump has not occurred, state==0 in this case,
prot_tag->retval is not used in the first place.
rescue
It’s been a little while, I’ll show the syntax tree of rescue again just in case.
▼Source Program
begin raise() rescue ArgumentError, TypeError 'error raised' end
▼ Its Syntax Tree ( nodedump-short )
NODE_BEGIN
nd_body:
NODE_RESCUE
nd_head:
NODE_FCALL
nd_mid = 3857 (raise)
nd_args = (null)
nd_resq:
NODE_RESBODY
nd_args:
NODE_ARRAY [
0:
NODE_CONST
nd_vid = 4733 (ArgumentError)
1:
NODE_CONST
nd_vid = 4725 (TypeError)
]
nd_body:
NODE_STR
nd_lit = "error raised":String
nd_head = (null)
nd_else = (null)
I’d like you to make sure that (the syntax tree of) the statement to be
rescue ed is “under” NODE_RESCUE.
▼ rb_eval() – NODE_RESCUE
2590 case NODE_RESCUE:
2591 retry_entry:
2592 {
2593 volatile VALUE e_info = ruby_errinfo;
2594
2595 PUSH_TAG(PROT_NONE);
2596 if ((state = EXEC_TAG()) == 0) {
2597 result = rb_eval(self, node->nd_head); /* evaluate the body */
2598 }
2599 POP_TAG();
2600 if (state == TAG_RAISE) { /* an exception occurred at the body */
2601 NODE * volatile resq = node->nd_resq;
2602
2603 while (resq) { /* deal with the rescue clause one by one */
2604 ruby_current_node = resq;
2605 if (handle_rescue(self, resq)) { /* If dealt with by this clause */
2606 state = 0;
2607 PUSH_TAG(PROT_NONE);
2608 if ((state = EXEC_TAG()) == 0) {
2609 result = rb_eval(self, resq->nd_body);
2610 } /* evaluate the rescue clause */
2611 POP_TAG();
2612 if (state == TAG_RETRY) { /* Since retry occurred, */
2613 state = 0;
2614 ruby_errinfo = Qnil; /* the exception is stopped */
2615 goto retry_entry; /* convert to goto */
2616 }
2617 if (state != TAG_RAISE) { /* Also by rescue and such */
2618 ruby_errinfo = e_info; /* the exception is stopped */
2619 }
2620 break;
2621 }
2622 resq = resq->nd_head; /* move on to the next rescue clause */
2623 }
2624 }
2625 else if (node->nd_else) { /* when there is an else clause, */
2626 if (!state) { /* evaluate it only when any exception has not occurred. */
2627 result = rb_eval(self, node->nd_else);
2628 }
2629 }
2630 if (state) JUMP_TAG(state); /* the jump was not waited for */
2631 }
2632 break;
(eval.c)
Even though the size is not small, it’s not difficult because it only simply
deal with the nodes one by one.
This is the first time handle_rescue() appeared,
but for some reasons we cannot look at this function now.
I’ll explain only its effects here. Its prototype is this,
static int handle_rescue(VALUE self, NODE *resq)
and it determines whether the currently occurring exception (ruby_errinfo) is
a subclass of the class that is expressed by resq (TypeError, for instance).
The reason why passing self is that it’s necessary to call rb_eval() inside
this function in order to evaluate resq.