Ruby Hacking Guide
Translated by Vincent ISAMBART
Chapter 18: Loading
Outline
Interface
At the Ruby level, there are two procedures that can be used for loading: `require` and `load`.
require 'uri' # load the uri library load '/home/foo/.myrc' # read a resource file
They are both normal methods, compiled and evaluated exactly like any other code. It means loading occurs after compilation gave control to the evaluation stage.
These two function each have their own use. ‘require’ is to load libraries, and `load` is to load an arbitrary file. Let’s see this in more details.
`require`
`require` has four features:
- the file is searched for in the load path
- it can load extension libraries
- the `.rb`/`.so` extension can be omitted
- a given file is never loaded more than once
Ruby’s load path is in the global variable `$:`, which contains an array of strings. For example, displaying the content of the `$:` in the environment I usually use would show:
% ruby -e 'puts $:' /usr/lib/ruby/site_ruby/1.7 /usr/lib/ruby/site_ruby/1.7/i686-linux /usr/lib/ruby/site_ruby /usr/lib/ruby/1.7 /usr/lib/ruby/1.7/i686-linux .
Calling `puts` on an array displays one element on each line so it’s easy to read.
As I ran `configure` using `—prefix=/usr`, the library path is `/usr/lib/ruby` and below, but if you compile it normally from the source code, the libraries will be in `/usr/local/lib/ruby` and below. In a Windows environment, there will also be a drive letter.
Then, let’s try to `require` the standard library `nkf.so` from the load path.
require 'nkf'
If the `require`d name has no extension, `require` silently compensates. First, it tries with `.rb`, then with `.so`. On some platforms it also tries the platform’s specific extension for extension libraries, for example `.dll` in a Windows environment or `.bundle` on Mac OS X.
Let’s do a simulation on my environment. `ruby` checks the following paths in sequential order.
/usr/lib/ruby/site_ruby/1.7/nkf.rb /usr/lib/ruby/site_ruby/1.7/nkf.so /usr/lib/ruby/site_ruby/1.7/i686-linux/nkf.rb /usr/lib/ruby/site_ruby/1.7/i686-linux/nkf.so /usr/lib/ruby/site_ruby/nkf.rb /usr/lib/ruby/site_ruby/nkf.so /usr/lib/ruby/1.7/nkf.rb /usr/lib/ruby/1.7/nkf.so /usr/lib/ruby/1.7/i686-linux/nkf.rb /usr/lib/ruby/1.7/i686-linux/nkf.so found!
`nkf.so` has been found in `/usr/lib/ruby/1.7/i686-linux`. Once the file has been found, `require`’s last feature (not loading the file more than once) locks the file. The locks are strings put in the global variable `$“`. In our case the string `”nkf.so"` has been put there. Even if the extension has been omitted when calling `require`, the file name in `$"` has the extension.
require 'nkf' # after loading nkf... p $" # ["nkf.so"] the file is locked require 'nkf' # nothing happens if we require it again p $" # ["nkf.so"] the content of the lock array does not change
There are two reasons for adding the missing extension. The first one is not to load it twice if the same file is later `require`d with its extension. The second one is to be able to load both `nkf.rb` and `nkf.so`. In fact the extensions are disparate (`.so .dll .bundle` etc.) depending on the platform, but at locking time they all become `.so`. That’s why when writing a Ruby program you can ignore the differences of extensions and consider it’s always `so`. So you can say that `ruby` is quite UNIX oriented.
By the way, `$“` can be freely modified even at the Ruby level so we cannot say it’s a strong lock. You can for example load an extension library multiple times if you clear `$”`.
`load`
`load` is a lot easier than `require`. Like `require`, it searches the file in `$:`. But it can only load Ruby programs. Furthermore, the extension cannot be omitted: the complete file name must always be given.
load 'uri.rb' # load the URI library that is part of the standard library
In this simple example we try to load a library, but the proper way to use `load` is for example to load a resource file giving its full path.
Flow of the whole process
If we roughly split it, “loading a file” can be split in:
- finding the file
- reading the file and mapping it to an internal form
- evaluating it
The only difference between `require` and `load` is how to find the file. The rest is the same in both.
We will develop the last evaluation part a little more. Loaded Ruby programs are basically evaluated at the top-level. It means the defined constants will be top-level constants and the defined methods will be function-style methods.
### mylib.rb MY_OBJECT = Object.new def my_p(obj) p obj end ### first.rb require 'mylib' my_p MY_OBJECT # we can use the constants and methods defined in an other file
Only the local variable scope of the top-level changes when the file changes. In other words, local variables cannot be shared between different files. You can of course share them using for example `Proc` but this has nothing to do with the load mechanism.
Some people also misunderstand the loading mechanism. Whatever the class you are in when you call `load`, it does not change anything. Even if, like in the following example, you load a file in the `module` statement, it does not serve any purpose, as everything that is at the top-level of the loaded file is put at the Ruby top-level.
require 'mylib' # whatever the place you require from, be it at the top-level module SandBox require 'mylib' # or in a module, the result is the same end
Highlights of this chapter
With the above knowledge in our mind, we are going to read. But because this time its specification is defined very particularly, if we simply read it, it could be just an enumeration of the codes. Therefore, in this chapter, we are going to reduce the target to the following 3 points:
- loading serialisation
- the repartition of the functions in the different source files
- how extension libraries are loaded
Regarding the first point, you will understand it when you see it.
For the second point, the functions that appear in this chapter come from 4 different files, `eval.c ruby.c file.c dln.c`. Why is this in this way? We’ll try to think about the realistic situation behind it.
The third point is just like its name says. We will see how the currently popular trend of execution time loading, more commonly referred to as plug-ins, works. This is the most interesting part of this chapter, so I’d like to use as many pages as possible to talk about it.
Searching the library
`rb_f_require()`
The body of `require` is `rb_f_require`. First, we will only look at the part concerning the file search. Having many different cases is bothersome so we will limit ourselves to the case when no file extension is given.
▼ `rb_f_require()` (simplified version)
5527 VALUE 5528 rb_f_require(obj, fname) 5529 VALUE obj, fname; 5530 { 5531 VALUE feature, tmp; 5532 char ext, *ftptr; / OK / 5533 int state; 5534 volatile int safe = ruby_safe_level; 5535 5536 SafeStringValue(fname); 5537 ext = strrchr(RSTRING→ptr, ‘.’); 5538 if (ext) { / …if the file extension has been given… / 5584 } 5585 tmp = fname; 5586 switch (rb_find_file_ext(&tmp, loadable_ext)) { 5587 case 0: 5588 break; 5589 5590 case 1: 5591 feature = fname = tmp; 5592 goto load_rb; 5593 5594 default: 5595 feature = tmp; 5596 fname = rb_find_file(tmp); 5597 goto load_dyna; 5598 } 5599 if (rb_feature_p(RSTRING→ptr, Qfalse)) 5600 return Qfalse; 5601 rb_raise(rb_eLoadError, “No such file to load — %s”, RSTRING→ptr); 5602 5603 load_dyna: / …load an extension library… / 5623 return Qtrue; 5624 5625 load_rb: / …load a Ruby program… */ 5648 return Qtrue; 5649 }5491 static const char const loadable_ext[] = { 5492 “.rb”, DLEXT, / DLEXT=“.so”, “.dll”, “.bundle”… / 5493 #ifdef DLEXT2 5494 DLEXT2, / DLEXT2=“.dll” on Cygwin, MinGW */ 5495 #endif 5496 0 5497 };
(eval.c)
In this function the `goto` labels `load_rb` and `load_dyna` are actually like subroutines, and the two variables `feature` and `fname` are more or less their parameters. These variables have the following meaning.
| variable | meaning | example |
|---|---|---|
| `feature` | the library file name that will be put in `$"` | `uri.rb`、`nkf.so` |
| `fname` | the full path to the library | `/usr/lib/ruby/1.7/uri.rb` |
The name `feature` can be found in the function `rb_feature_p()`. This function checks if a file has been locked (we will look at it just after).
The functions actually searching for the library are `rb_find_file()` and `rb_find_file_ext()`. `rb_find_file()` searches a file in the load path `$’`. `rb_find_file_ext()` does the same but the difference is that it takes as a second parameter a list of extensions (i.e. `loadable_ext`) and tries them in sequential order.
Below we will first look entirely at the file searching code, then we will look at the code of the `require` lock in `load_rb`.
`rb_find_file()`
First the file search continues in `rb_find_file()`. This function searches the file `path` in the global load path `$‘` (`rb_load_path`). The string contamination check is tiresome so we’ll only look at the main part.
▼ `rb_find_file()` (simplified version)
2494 VALUE 2495 rb_find_file(path) 2496 VALUE path; 2497 { 2498 VALUE tmp; 2499 char *f = RSTRING→ptr; 2500 char *lpath;2530 if (rb_load_path) { 2531 long i; 2532 2533 Check_Type(rb_load_path, T_ARRAY); 2534 tmp = rb_ary_new(); 2535 for (i=0;i<RARRAY→len;i++) { 2536 VALUE str = RARRAY→ptr[i]; 2537 SafeStringValue(str); 2538 if (RSTRING→len > 0) { 2539 rb_ary_push(tmp, str); 2540 } 2541 } 2542 tmp = rb_ary_join(tmp, rb_str_new2(PATH_SEP)); 2543 if (RSTRING→len == 0) { 2544 lpath = 0; 2545 } 2546 else { 2547 lpath = RSTRING→ptr; 2551 } 2552 }
2560 f = dln_find_file(f, lpath); 2561 if (file_load_ok(f)) { 2562 return rb_str_new2(f); 2563 } 2564 return 0; 2565 }
(file.c)
If we write what happens in Ruby we get the following:
tmp = [] # make an array $:.each do |path| # repeat on each element of the load path tmp.push path if path.length > 0 # check the path and push it end lpath = tmp.join(PATH_SEP) # concatenate all elements in one string separated by PATH_SEP dln_find_file(f, lpath) # main processing
`PATH_SEP` is the `path separator`: `‘:’` under UNIX, `‘;’` under Windows. `rb_ary_join()` creates a string by putting it between the different elements. In other words, the load path that had become an array is back to a string with a separator.
Why? It’s only because `dln_find_file()` takes the paths as a string with `PATH_SEP` as a separator. But why is `dln_find_file()` implemented like that? It’s just because `dln.c` is not a library for `ruby`. Even if it has been written by the same author, it’s a general purpose library. That’s precisely for this reason that when I sorted the files by category in the Introduction I put this file in the Utility category. General purpose libraries cannot receive Ruby objects as parameters or read `ruby` global variables.
`dln_find_file()` also expands for example `~` to the home directory, but in fact this is already done in the omitted part of `rb_find_file()`. So in `ruby`‘s case it’s not necessary.
Loading wait
Here, file search is finished quickly. Then comes is the loading code. Or more accurately, it is “up to just before the load”. The code of `rb_f_require()`’s `load_rb` has been put below.
▼ `rb_f_require():load_rb`
5625 load_rb: 5626 if (rb_feature_p(RSTRING→ptr, Qtrue)) 5627 return Qfalse; 5628 ruby_safe_level = 0; 5629 rb_provide_feature(feature); 5630 /* the loading of Ruby programs is serialised / 5631 if (!loading_tbl) { 5632 loading_tbl = st_init_strtable(); 5633 } 5634 / partial state / 5635 ftptr = ruby_strdup(RSTRING→ptr); 5636 st_insert(loading_tbl, ftptr, curr_thread); / …load the Ruby program and evaluate it… / 5643 st_delete(loading_tbl, &ftptr, 0); / loading done */ 5644 free(ftptr); 5645 ruby_safe_level = safe;(eval.c)
Like mentioned above, `rb_feature_p()` checks if a lock has been put in `$“`. And `rb_provide_feature()` pushes a string in `$”`, in other words locks the file.
The problem comes after. Like the comment says “the loading of Ruby programs is serialised”. In other words, a file can only be loaded from one thread, and if during the loading another thread tries to load the same file, that thread will wait for the first loading to be finished. If it were not the case:
Thread.fork {
require 'foo' # At the beginning of require, foo.rb is added to $"
} # However the thread changes during the evaluation of foo.rb
require 'foo' # foo.rb is already in $" so the function returns immediately
# (A) the classes of foo are used...
By doing something like this, even though the `foo` library is not really loaded, the code at (A) ends up being executed.
The process to enter the waiting state is simple. A `st_table` is created in `loading_tbl`, the association “`feature=>`waiting thread” is recorded in it. `curr_thread` is in `eval.c`’s functions, its value is the current running thread.
The mechanism to enter the waiting state is very simple. A `st_table` is created in the `loading_tbl` global variable, and a “`feature`=>`loading thread`” association is created. `curr_thread` is a variable from `eval.c`, and its value is the currently running thread. That makes an exclusive lock. And in `rb_feature_p()`, we wait for the loading thread to end like the following.
▼ `rb_feature_p()` (second half)
5477 rb_thread_t th;
5478
5479 while (st_lookup(loading_tbl, f, &th)) {
5480 if (th == curr_thread) {
5481 return Qtrue;
5482 }
5483 CHECK_INTS;
5484 rb_thread_schedule();
5485 }
(eval.c)
When `rb_thread_schedule()` is called, the control is transferred to an other thread, and this function only returns after the control returned back to the thread where it was called. When the file name disappears from `loading_tbl`, the loading is finished so the function can end. The `curr_thread` check is not to lock itself (figure 1).
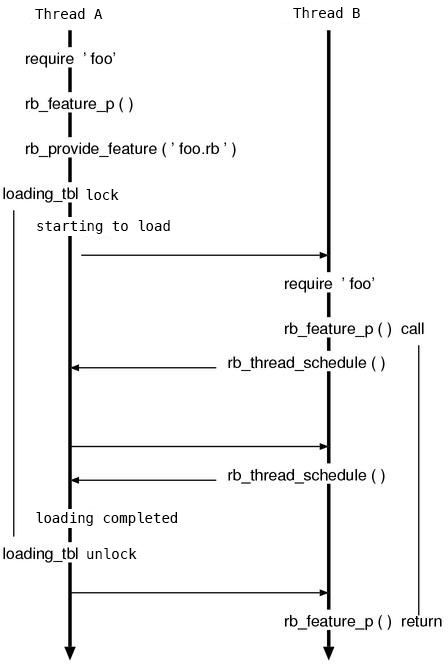
Figure 1: Serialisation of loads
Loading of Ruby programs
`rb_load()`
We will now look at the loading process itself. Let’s start by the part inside `rb_f_require()`’s `load_rb` loading Ruby programs.
▼ `rb_f_require()-load_rb-` loading
5638 PUSH_TAG(PROT_NONE);
5639 if ((state = EXEC_TAG()) == 0) {
5640 rb_load(fname, 0);
5641 }
5642 POP_TAG();
(eval.c)
The `rb_load()` which is called here is actually the “meat” of the Ruby-level `load`. This means it needs to search once again, but looking at the same procedure once again is too much trouble. Therefore, that part is omitted in the below codes.
And the second argument `wrap` is folded with 0 because it is 0 in the above calling code.
▼ `rb_load()` (simplified edition)
void
rb_load(fname, /* wrap=0 */)
VALUE fname;
{
int state;
volatile ID last_func;
volatile VALUE wrapper = 0;
volatile VALUE self = ruby_top_self;
NODE *saved_cref = ruby_cref;
PUSH_VARS();
PUSH_CLASS();
ruby_class = rb_cObject;
ruby_cref = top_cref; /* (A-1) change CREF */
wrapper = ruby_wrapper;
ruby_wrapper = 0;
PUSH_FRAME();
ruby_frame→last_func = 0;
ruby_frame→last_class = 0;
ruby_frame→self = self; /* (A-2) change ruby_frame→cbase */
ruby_frame→cbase = (VALUE)rb_node_newnode(NODE_CREF,ruby_class,0,0);
PUSH_SCOPE();
/* at the top-level the visibility is private by default */
SCOPE_SET(SCOPE_PRIVATE);
PUSH_TAG(PROT_NONE);
ruby_errinfo = Qnil; /* make sure it’s nil */
state = EXEC_TAG();
last_func = ruby_frame→last_func;
if (state == 0) {
NODE *node;
/* (B) this is dealt with as eval for some reasons */
ruby_in_eval++;
rb_load_file(RSTRING→ptr);
ruby_in_eval—;
node = ruby_eval_tree;
if (ruby_nerrs == 0) { /* no parse error occurred */
eval_node(self, node);
}
}
ruby_frame→last_func = last_func;
POP_TAG();
ruby_cref = saved_cref;
POP_SCOPE();
POP_FRAME();
POP_CLASS();
POP_VARS();
ruby_wrapper = wrapper;
if (ruby_nerrs > 0) { /* a parse error occurred */
ruby_nerrs = 0;
rb_exc_raise(ruby_errinfo);
}
if (state) jump_tag_but_local_jump(state);
if (!NIL_P(ruby_errinfo)) /* an exception was raised during the loading */
rb_exc_raise(ruby_errinfo);
}
Just after we thought we’ve been through the storm of stack manipulations we entered again. Although this is tough, let’s cheer up and read it.
As the long functions usually are, almost all of the code are occupied by the idioms. `PUSH`/`POP`, tag protecting and re-jumping. Among them, what we want to focus on is the things on (A) which relate to `CREF`. Since a loaded program is always executed on the top-level, it sets aside (not push) `ruby_cref` and brings back `top_cref`. `ruby_frame→cbase` also becomes a new one.
And one more place, at (B) somehow `ruby_in_eval` is turned on. What is the part influenced by this variable? I investigated it and it turned out that it seems only `rb_compile_error()`. When `ruby_in_eval` is true, the message is stored in the exception object, but when it is not true, the message is printed to `stderr`. In other words, when it is a parse error of the main program of the command, it wants to print directly to `stderr`, but when inside of the evaluator, it is not appropriate so it stops to do it. It seems the “eval” of `ruby_in_eval` means neither the `eval` method nor the `eval()` function but “evaluate” as a general noun. Or, it’s possible it indicates `eval.c`.
`rb_load_file()`
Then, all of a sudden, the source file is `ruby.c` here. Or to put it more accurately, essentially it is favorable if the entire loading code was put in `ruby.c`, but `rb_load()` has no choice but to use `PUSH_TAG` and such. Therefore, putting it in `eval.c` is inevitable. If it were not the case, all of them would be put in `eval.c` in the first place.
Then, it is `rb_load_file()`.
▼ `rb_load_file()`
865 void
866 rb_load_file(fname)
867 char *fname;
868 {
869 load_file(fname, 0);
870 }
(ruby.c)
Delegated entirely. The second argument `script` of `load_file()` is a boolean value and it indicates whether it is loading the file of the argument of the `ruby` command. Now, because we’d like to assume we are loading a library, let’s fold it by replacing it with `script=0`. Furthermore, in the below code, also thinking about the meanings, non essential things have already been removed.
▼ `load_file()` (simplified edition)
static void
load_file(fname, /* script=0 */)
char *fname;
{
VALUE f;
{
FILE *fp = fopen(fname, "r"); (A)
if (fp == NULL) {
rb_load_fail(fname);
}
fclose(fp);
}
f = rb_file_open(fname, "r"); (B)
rb_compile_file(fname, f, 1); (C)
rb_io_close(f);
}
(A) The call to `fopen()` is to check if the file can be opened. If there is no problem, it’s immediately closed. It may seem a little useless but it’s an extremely simple and yet highly portable and reliable way to do it.
(B) The file is opened once again, this time using the Ruby level library `File.open`. The file was not opened with `File.open` from the beginning so as not to raise any Ruby exception. Here if any exception occurred we would like to have a loading error, but getting the errors related to `open`, for example `Errno::ENOENT`, `Errno::EACCESS`…, would be problematic. We are in `ruby.c` so we cannot stop a tag jump.
(C) Using the parser interface `rb_compile_file()`, the program is read from an `IO` object, and compiled in a syntax tree. The syntax tree is added to `ruby_eval_tree` so there is no need to get the result.
That’s all for the loading code. Finally, the calls were quite deep so the callgraph of `rb_f_require()` is shown bellow.
rb_f_require ....eval.c
rb_find_file ....file.c
dln_find_file ....dln.c
dln_find_file_1
rb_load
rb_load_file ....ruby.c
load_file
rb_compile_file ....parse.y
eval_node
You must bring callgraphs on a long trip. It’s common knowledge.
The number of `open` required for loading
Previously, there was `open` used just to check if a file can be open, but in fact, during the loading process of `ruby`, additionally other functions such as `rb_find_file_ext()` also internally do checks by using `open`. How many times is `open()` called in the whole process?
If you’re wondering that, just actually counting it is the right attitude as a programmer. We can easily count it by using a system call tracer. The tool to use would be `strace` on Linux, `truss` on Solaris, `ktrace` or `truss` on BSD. Like this, for each OS, the name is different and there’s no consistency, but you can find them by googling.
If you’re using Windows, probably your IDE will have a tracer built in. Well, as my main environment is Linux, I looked using `strace`.
The output is done on `stderr` so it was redirected using `2>&1`.
% strace ruby -e 'require "rational"' 2>&1 | grep '^open'
open("/etc/ld.so.preload", O_RDONLY) = -1 ENOENT
open("/etc/ld.so.cache", O_RDONLY) = 3
open("/usr/lib/libruby-1.7.so.1.7", O_RDONLY) = 3
open("/lib/libdl.so.2", O_RDONLY) = 3
open("/lib/libcrypt.so.1", O_RDONLY) = 3
open("/lib/libc.so.6", O_RDONLY) = 3
open("/usr/lib/ruby/1.7/rational.rb", O_RDONLY|O_LARGEFILE) = 3
open("/usr/lib/ruby/1.7/rational.rb", O_RDONLY|O_LARGEFILE) = 3
open("/usr/lib/ruby/1.7/rational.rb", O_RDONLY|O_LARGEFILE) = 3
open("/usr/lib/ruby/1.7/rational.rb", O_RDONLY|O_LARGEFILE) = 3
Until the `open` of `libc.so.6`, it is the `open` used in the implementation of dynamic links, and there are the other four `open`s. Thus it seems the three of them are useless.
Loading of extension libraries
`rb_f_require()`-`load_dyna`
This time we will see the loading of extension libraries. We will start with `rb_f_require()`’s `load_dyna`. However, we do not need the part about locking anymore so it was removed.
▼ `rb_f_require()`-`load_dyna`
5607 {
5608 int volatile old_vmode = scope_vmode;
5609
5610 PUSH_TAG(PROT_NONE);
5611 if ((state = EXEC_TAG()) == 0) {
5612 void *handle;
5613
5614 SCOPE_SET(SCOPE_PUBLIC);
5615 handle = dln_load(RSTRING→ptr);
5616 rb_ary_push(ruby_dln_librefs, LONG2NUMhandle));
5617 }
5618 POP_TAG();
5619 SCOPE_SET(old_vmode);
5620 }
5621 if (state) JUMP_TAG(state);
(eval.c)
By now, there is very little here which is novel. The tags are used only in the way of the idiom, and to save/restore the visibility scope is done in the way we get used to see. All that remains is `dln_load()`. What on earth is that for? For the answer, continue to the next section.
Brush up about links
`dln_load()` is loading an extension library, but what does loading an extension library mean? To talk about it, we need to dramatically roll back the talk to the physical world, and start with about links.
I think compiling C programs is, of course, not a new thing for you. Since I’m using `gcc` on Linux, I can create a runnable program in the following manner.
% gcc hello.c
According to the file name, this is probably an “Hello, World!” program. In UNIX, `gcc` outputs a program into a file named `a.out` by default, so you can subsequently execute it in the following way:
% ./a.out Hello, World!
It is created properly.
By the way, what is `gcc` actually doing here? Usually we just say “compile” or “compile”, but actually
- preprocess (`cpp`)
- compile C into assembly (`cc`)
- assemble the assembly language into machine code (`as`)
- link (`ld`)
there are these four steps. Among them, preprocessing and compiling and assembling are described in a lot of places, but the description often ends without clearly describing about the linking phase. It is like a history class in school which would never reach “modern age”. Therefore, in this book, trying to provide the extinguished part, I’ll briefly summarize what is linking.
A program finished the assembling phase becomes an “object file” in somewhat format. The following formats are some of such formats which are major.
- ELF, Executable and Linking Format (recent UNIX)
- `a.out`, assembler output (relatively old UNIX)
- COFF, Common Object File Format (Win32)
It might go without saying that the `a.out` as an object file format and the `a.out` as a default output file name of `cc` are totally different things. For example, on modern Linux, when we create it ordinarily, the `a.out` file in ELF format is created.
And, how these object file formats differ each other is not important now. What we have to recognize now is, all of these object files can be considered as “a set of names”. For example, the function names and the variable names which exist in this file.
And, sets of names contained in the object file have two types.
- set of necessary names (for instance, the external functions called internally. e.g. `printf`)
- set of providing names (for instance, the functions defined internally. e.g. `hello`)
And linking is, when gathering multiple object files, checking if “the set of providing names” contains “the set of necessary names” entirely, and connecting them each other. In other words, pulling the lines from all of “the necessary names”, each line must be connected to one of “the providing names” of a particular object file. (Figure. 2) To put this in technical terms, it is resolving undefined symbols.
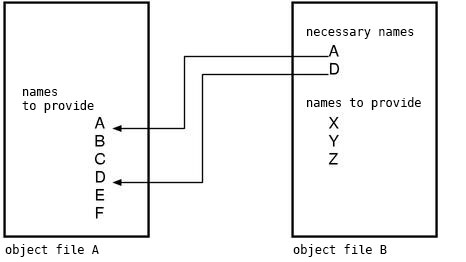
Figure 2: object files and linking
Logically this is how it is, but in reality a program can’t run only because of this. At least, C programs cannot run without converting the names to the addresses (numbers).
So, after the logical conjunctions, the physical conjunctions become necessary. We have to map object files into the real memory space and substitute the all names with numbers. Concretely speaking, for instance, the addresses to jump to on function calls are adjusted here.
And, based on the timing when to do these two conjunctions, linking is divided into two types: static linking and dynamic linking. Static linking finishes the all phases during the compile time. On the other hand, dynamic linking defers some of the conjunctions to the executing time. And linking is finally completed when executing.
However, what explained here is a very simple idealistic model, and it has an aspect distorting the reality a lot. Logical conjunctions and physical conjunctions are not so completely separated, and “an object file is a set of names” is too naive. But the behavior around this considerably differs depending on each platform, describing seriously would end up with one more book. To obtain the realistic level knowledge, additionally, “Expert C Programming: Deep C Secrets” by Peter van der Linden, “Linkers and Loaders” by John R.Levine I recommend to read these books.
Linking that is truly dynamic
And finally we get into our main topic. The “dynamic” in “dynamic linking” naturally means it “occurs at execution time”, but what people usually refer to as “dynamic linking” is pretty much decided already at compile time. For example, the names of the needed functions, and which library they can be found in, are already known. For instance, if you need `cos()`, you know it’s in `libm`, so you use `gcc -lm`. If you didn’t specify the correct library at compile time, you’d get a link error.
But extension libraries are different. Neither the names of the needed functions, or the name of the library which defines them are known at compile time. We need to construct a string at execution time and load and link. It means that even “the logical conjunctions” in the sense of the previous words should be done entirely at execution time. In order to do it, another mechanism that is a little different form the ordinal dynamic linkings is required.
This manipulation, linking that is entirely decided at runtime, is usually called “dynamic load”.
Dynamic load API
I’ve finished to explain the concept. The rest is how to do that dynamic loading. This is not a difficult thing. Usually there’s a specific API prepared in the system, we can accomplish it by merely calling it.
For example, what is relatively broad for UNIX is the API named `dlopen`. However, I can’t say “It is always available on UNIX”. For example, for a little previous HP-UX has a totally different interface, and a NeXT-flavor API is used on Mac OS X. And even if it is the same `dlopen`, it is included in `libc` on BSD-derived OS, and it is attached from outside as `libdl` on Linux. Therefore, it is desperately not portable. It differs even among UNIX-based platforms, it is obvious to be completely different in the other Operating Systems. It is unlikely that the same API is used.
Then, how `ruby` is doing is, in order to absorb the totally different interfaces, the file named `dln.c` is prepared. `dln` is probably the abbreviation of “dynamic link”. `dln_load()` is one of functions of `dln.c`.
Where dynamic loading APIs are totally different each other, the only saving is the usage pattern of API is completely the same. Whichever platform you are on,
- map the library to the address space of the process
- take the pointers to the functions contained in the library
- unmap the library
it consists of these three steps. For example, if it is `dlopen`-based API,
- `dlopen`
- `dlsym`
- `dlclose`
are the correspondences. If it is Win32 API,
- `LoadLibrary` (or `LoadLibraryEx`)
- `GetProcAddress`
- `FreeLibrary`
are the correspondences.
At last, I’ll talk about what `dln_load()` is doing by using these APIs. It is, in fact, calling `Init_xxxx()`. By reaching here, we finally become to be able to illustrate the entire process of `ruby` from the invocation to the completion without any lacks. In other words, when `ruby` is invoked, it initializes the evaluator and starts evaluating a program passed in somewhat way. If `require` or `load` occurs during the process, it loads the library and transfers the control. Transferring the control means parsing and evaluating if it is a Ruby library and it means loading and linking and finally calling `Init_xxxx()` if it is an extension library.
`dln_load()`
Finally, we’ve reached the content of `dln_load()`. `dln_load()` is also a long function, but its structure is simple because of some reasons. Take a look at the outline first.
▼ `dln_load()` (outline)
void*
dln_load(file)
const char file;
{
#if defined _WIN32 && !defined CYGWIN
load with Win32 API
#else
initialization depending on each platform
#ifdef each platform
……routines for each platform……
#endif
#endif
#if !defined(AIX) && !defined(NeXT)
failed:
rbloaderror(“%s – %s”, error, file);
#endif
return 0; / dummy return */
}
This way, the part connecting to the main is completely separated based on each platform. When thinking, we only have to think about one platform at a time. Supported APIs are as follows:
- `dlopen` (Most of UNIX)
- `LoadLibrary` (Win32)
- `shl_load` (a bit old HP-UX)
- `a.out` (very old UNIX)
- `rld_load` (before `NeXT4`)
- `dyld` (`NeXT` or Mac OS X)
- `get_image_symbol` (BeOS)
- `GetDiskFragment` (Mac Os 9 and before)
- `load` (a bit old AIX)
`dln_load()`-`dlopen()`
First, let’s start with the API code for the `dlopen` series.
▼ `dln_load()`-`dlopen()`
1254 void*
1255 dln_load(file)
1256 const char file;
1257 {
1259 const char *error = 0;
1260 #define DLN_ERROR() (error = dln_strerror(),\
strcpy(ALLOCA_N(char, strlen(error) + 1), error))
1298 char *buf;
1299 / write a string “Init_xxxx” to buf (the space is allocated with alloca) */
1300 init_funcname(&buf, file);
1304 {
1305 void handle;
1306 void (init_fct)();
1307
1308 #ifndef RTLD_LAZY
1309 # define RTLD_LAZY 1
1310 #endif
1311 #ifndef RTLD_GLOBAL
1312 # define RTLD_GLOBAL 0
1313 #endif
1314
1315 /* (A) load the library /
1316 if ((handle = (void)dlopen(file, RTLD_LAZY | RTLD_GLOBAL))
== NULL) {
1317 error = dln_strerror();
1318 goto failed;
1319 }
1320
/* (B) get the pointer to Init_xxxx() /
1321 init_fct = (void()())dlsym(handle, buf);
1322 if (init_fct == NULL) {
1323 error = DLN_ERROR();
1324 dlclose(handle);
1325 goto failed;
1326 }
1327 /* © call Init_xxxx() /
1328 (init_fct)();
1329
1330 return handle;
1331 }
1576 failed:
1577 rb_loaderror(“%s – %s”, error, file);
1580 }
(dln.c)
(A) the `RTLD_LAZY` as the argument of `dlopen()` indicates “resolving the undefined symbols when the functions are actually demanded” The return value is the mark (handle) to distinguish the library and we always need to pass it when using `dl*()`.
(B) `dlsym()` gets the function pointer from the library specified by the handle. If the return value is `NULL`, it means failure. Here, getting the pointer to `Init_xxxx()` If the return value is `NULL`, it means failure. Here, the pointer to `Init_xxxx()` is obtained and called.
`dlclose()` is not called here. Since the pointers to the functions of the loaded library are possibly returned inside `Init_xxx()`, it is troublesome if `dlclose()` is done because the entire library would be disabled to use. Thus, we can’t call `dlclose()` until the process will be finished.
`dln_load()` — Win32
As for Win32, `LoadLibrary()` and `GetProcAddress()` are used. It is very general Win32 API which also appears on MSDN.
▼ `dln_load()`-Win32
1254 void*
1255 dln_load(file)
1256 const char *file;
1257 {
1264 HINSTANCE handle;
1265 char winfile[MAXPATHLEN];
1266 void (init_fct)();
1267 char *buf;
1268
1269 if (strlen(file) >= MAXPATHLEN) rb_loaderror(“filename too long”);
1270
1271 / write the “Init_xxxx” string to buf (the space is allocated with alloca) /
1272 init_funcname(&buf, file);
1273
1274 strcpy(winfile, file);
1275
1276 / load the library /
1277 if ((handle = LoadLibrary(winfile)) == NULL) {
1278 error = dln_strerror();
1279 goto failed;
1280 }
1281
1282 if ((init_fct = (void()())GetProcAddress(handle, buf)) == NULL) {
1283 rb_loaderror(“%s – %s\n%s”, dln_strerror(), buf, file);
1284 }
1285
1286 /* call Init_xxxx() /
1287 (init_fct)();
1288 return handle;
1576 failed:
1577 rb_loaderror(“%s – %s”, error, file);
1580 }
(dln.c)
Doing `LoadLibrary()` then `GetProcAddress()`. The pattern is so equivalent that nothing is left to say, I decided to end this chapter.