Ruby Hacking Guide
Chapter 14: Context
The range covered by this chapter is really broad. First of all, I’ll describe about how the internal state of the evaluator is expressed. After that, as an actual example, we’ll read how the state is changed on a class definition statement. Subsequently, we’ll examine how the internal state influences method definition statements. Lastly, we’ll observe how the both statements change the behaviors of the variable definitions and the variable references.
The Ruby stack
Context and Stack
With an image of a typical procedural language, each time calling a procedure, the information which is necessary to execute the procedure such as the local variable space and the place to return is stored in a struct (a stack frame) and it is pushed on the stack. When returning from a procedure, the struct which is on the top of the stack is popped and the state is returned to the previous method. The executing image of a C program which was explained at Chapter 5: Garbage collection is a perfect example.
What to be careful about here is, what is changing during the execution is only
the stack, on the contrary, the program remains unchanged wherever it is.
For example, if it is “a reference to the local variable i”, there’s just an
order of “give me i of the current frame”, it is not written as “give me i
of that frame”. In other words, “only” the state of the stack influences the
consequence. This is why,
even if a procedure is called anytime and any number of times,
we only have to write its code once (Fig. 1).
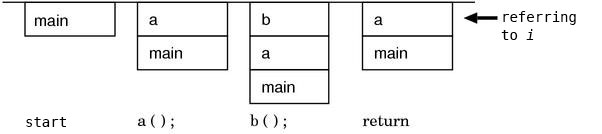
Fig.1: What is changing is only the stack
The execution of Ruby is also basically nothing but chained calls of methods which are procedures, so essentially it has the same image as above. In other words, with the same code, things being accessed such as local variable scope and the block local scope will be changing. And these kind of scopes are expressed by stacks.
However in Ruby, for instance, you can temporarily go back to the scope
previously used by using iterators or Proc.
This cannot be implemented with just simply pushing/popping a stack.
Therefore the frames of the Ruby stack will be intricately rearranged during
execution. Although I call it “stack”, it could be better to consider it
as a list.
Other than the method call, the local variable scope can also be changed on the class definitions. So, the method calls does not match the transitions of the local variable scope. Since there are also blocks, it’s necessary to handle them separately. For these various reasons, surprisingly, there are seven stacks.
| Stack Pointer | Stack Frame Type | Description |
|---|---|---|
ruby_frame |
struct FRAME |
the records of method calls |
ruby_scope |
struct SCOPE |
the local variable scope |
ruby_block |
struct BLOCK |
the block scope |
ruby_iter |
struct iter |
whether or not the current FRAME is an iterator |
ruby_class |
VALUE |
the class to define methods on |
ruby_cref |
NODE ( NODE_CREF ) |
the class nesting information |
C has only one stack and Ruby has seven stacks, by simple arithmetic, the executing image of Ruby is at least seven times more complicated than C. But it is actually not seven times at all, it’s at least twenty times more complicated.
First, I’ll briefly describe about these stacks and their stack frame structs.
The defined file is either eval.c or evn.h. Basically these stack frames
are touched only by eval.c … is what it should be if it were possible,
but gc.c needs to know the struct types when marking,
so some of them are exposed in env.h.
Of course, marking could be done in the other file but gc.c, but it requires
separated functions which cause slowing down. The ordinary programs had better
not care about such things, but both the garbage collector and the core of the
evaluator is the ruby’s biggest bottleneck, so it’s quite worth to optimize
even for just one method call.
ruby_frame
ruby_frame is a stack to record method calls. The stack frame struct is
struct FRAME. This terminology is a bit confusing but please be aware that
I’ll distinctively write it just a frame when it means a “stack frame” as a
general noun and FRAME when it means struct FRAME.
▼ ruby_frame
16 extern struct FRAME {
17 VALUE self; /* self */
18 int argc; /* the argument count */
19 VALUE *argv; /* the array of argument values */
20 ID last_func; /* the name of this FRAME (when called) */
21 ID orig_func; /* the name of this FRAME (when defined) */
22 VALUE last_class; /* the class of last_func's receiver */
23 VALUE cbase; /* the base point for searching constants and class variables */
24 struct FRAME *prev;
25 struct FRAME *tmp; /* to protect from GC. this will be described later */
26 struct RNode *node; /* the file name and the line number of the currently executed line. */
27 int iter; /* is this called with a block? */
28 int flags; /* the below two */
29 } *ruby_frame;
33 #define FRAME_ALLOCA 0 /* FRAME is allocated on the machine stack */
34 #define FRAME_MALLOC 1 /* FRAME is allocated by malloc */
(env.h)
First af all, since there’s the prev member, you can infer that the stack is
made of a linked list. (Fig.2)
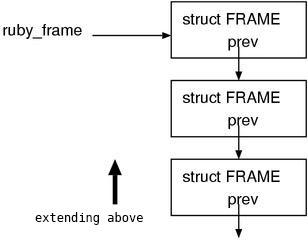
Fig.2: ruby_frame
The fact that ruby_xxxx points to the top stack frame is common to all stacks
and won’t be mentioned every time.
The first member of the struct is self.
There is also self in the arguments of rb_eval(),
but why this struct remembers another self ?
This is for the C-level functions. More precisely, it’s for rb_call_super() that is
corresponding to super. In order to execute super, it requires the receiver
of the current method, but the caller side of rb_call_super() could not have
such information. However, the chain of rb_eval() is interrupted before the
time when the execution of the user-defined C code starts. Therefore, the
conclusion is that there need a way to obtain the information of self out of
nothing. And, FRAME is the right place to store it.
Thinking a little further, It’s mysterious that there are argc and argv.
Because parameter variables are local variables after all, it is unnecessary to
preserve the given arguments after assigning them into the local variable with
the same names at the beginning of the method, isn’t it?
Then, what is the use of them ? The answer is that this is actually for
super again. In Ruby, when calling super without any arguments, the values of
the parameter variables of the method will be passed to the method of the
superclass.
Thus, (the local variable space for) the parameter variables must be reserved.
Additionally, the difference between last_func and orig_func will come
out in the cases like when the method is alias ed.
For instance,
class C def orig() end alias ali orig end C.new.ali
in this case, last_func=ali and orig_func=orig.
Not surprisingly, these members also have to do with super.
ruby_scope
ruby_scope is the stack to represent the local variable scope. The method and
class definition statements, the module definition statements and the singleton
class definition statements, all of them are different scopes. The stack frame
struct is struct SCOPE.
I’ll call this frame SCOPE.
▼ ruby_scope
36 extern struct SCOPE {
37 struct RBasic super;
38 ID *local_tbl; /* an array of the local variable names */
39 VALUE *local_vars; /* the space to store local variables */
40 int flags; /* the below four */
41 } *ruby_scope;
43 #define SCOPE_ALLOCA 0 /* local_vars is allocated by alloca */
44 #define SCOPE_MALLOC 1 /* local_vars is allocated by malloc */
45 #define SCOPE_NOSTACK 2 /* POP_SCOPE is done */
46 #define SCOPE_DONT_RECYCLE 4 /* Proc is created with this SCOPE */
(env.h)
Since the first element is struct RBasic, this is a Ruby object. This is in
order to handle Proc objects. For example, let’s try to think about the case
like this:
def make_counter
lvar = 0
return Proc.new { lvar += 1 }
end
cnt = make_counter()
p cnt.call # 1
p cnt.call # 2
p cnt.call # 3
cnt = nil # cut the reference. The created Proc finally becomes unnecessary here.
The Proc object created by this method will persist longer than the method that
creates it. And, because the Proc can refer to the local variable lvar,
the local variables must be preserved until the Proc will disappear.
Thus, if it were not handled by the garbage collector, no one can determine the
time to free.
There are two reasons why struct SCOPE is separated from struct FRAME.
Firstly, the things like class definition statements are not method
calls but create distinct local variable scopes.
Secondly, when a called method is defined in C the Ruby’s local
variable space is unnecessary.
ruby_block
struct BLOCK is the real body of a Ruby’s iterator block or a Proc object,
it is also kind of a snapshot of the evaluator at some point.
This frame will also be briefly written as BLOCK as in the same manner as
FRAME and SCOPE.
▼ ruby_block
580 static struct BLOCK *ruby_block;
559 struct BLOCK {
560 NODE *var; /* the block parameters(mlhs) */
561 NODE *body; /* the code of the block body */
562 VALUE self; /* the self when this BLOCK is created */
563 struct FRAME frame; /* the copy of ruby_frame when this BLOCK is created */
564 struct SCOPE *scope; /* the ruby_scope when this BLOCK is created */
565 struct BLOCKTAG *tag; /* the identity of this BLOCK */
566 VALUE klass; /* the ruby_class when this BLOCK is created */
567 int iter; /* the ruby_iter when this BLOCK is created */
568 int vmode; /* the scope_vmode when this BLOCK is created */
569 int flags; /* BLOCK_D_SCOPE, BLOCK_DYNAMIC */
570 struct RVarmap *dyna_vars; /* the block local variable space */
571 VALUE orig_thread; /* the thread that creates this BLOCK */
572 VALUE wrapper; /* the ruby_wrapper when this BLOCK is created */
573 struct BLOCK *prev;
574 };
553 struct BLOCKTAG {
554 struct RBasic super;
555 long dst; /* destination, that is, the place to return */
556 long flags; /* BLOCK_DYNAMIC, BLOCK_ORPHAN */
557 };
576 #define BLOCK_D_SCOPE 1 /* having distinct block local scope */
577 #define BLOCK_DYNAMIC 2 /* BLOCK was taken from a Ruby program */
578 #define BLOCK_ORPHAN 4 /* the FRAME that creates this BLOCK has finished */
(eval.c)
Note that frame is not a pointer. This is because the entire content of
struct FRAME will be all copied and preserved. The entire struct FRAME is
(for better performance) allocated on the machine stack, but BLOCK could
persist longer than the FRAME that creates it, the preservation is a
preparation for that case.
Additionally, struct BLOCKTAG is separated in order to detect the same block
when multiple Proc objects are created from the block. The Proc objects
which were created from the one same block have the same BLOCKTAG.
ruby_iter
The stack ruby_iter indicates whether currently calling method is an iterator
(whether it is called with a block). The frame is struct iter.
But for consistency I’ll call it ITER.
▼ ruby_iter
767 static struct iter *ruby_iter;
763 struct iter {
764 int iter; /* the below three */
765 struct iter *prev;
766 };
769 #define ITER_NOT 0 /* the currently evaluated method is not an iterator */
770 #define ITER_PRE 1 /* the method which is going to be evaluated next is an iterator */
771 #define ITER_CUR 2 /* the currently evaluated method is an iterator */
(eval.c)
Although for each method we can determine whether it is an iterator or not,
there’s another struct that is distinct from struct FRAME. Why?
It’s obvious you need to inform it to the method when “it is an iterator”,
but you also need to inform the fact when “it is not an iterator”.
However, pushing a whole BLOCK just for this is very heavy. It will also
cause that in the caller side the procedures such as variable references
would needlessly increase.
Thus, it’s better to push the smaller and lighter ITER instead of BLOCK.
This will be discussed in detail in Chapter 16: Blocks.
ruby_dyna_vars
The block local variable space. The frame struct is struct RVarmap that has
already seen in Part 2. From now on, I’ll call it just VARS.
▼ struct RVarmap
52 struct RVarmap {
53 struct RBasic super;
54 ID id; /* the name of the variable */
55 VALUE val; /* the value of the variable */
56 struct RVarmap *next;
57 };
(env.h)
Note that a frame is not a single struct RVarmap but a list of the structs (Fig.3).
And each frame is corresponding to a local variable scope.
Since it corresponds to “local variable scope” and not “block local variable scope”,
for instance, even if blocks are nested, only a single list is used to express.
The break between blocks are similar to the one of the parser,
it is expressed by a RVarmap (header) whose id is 0.
Details are deferred again. It will be explained in Chapter 16: Blocks.
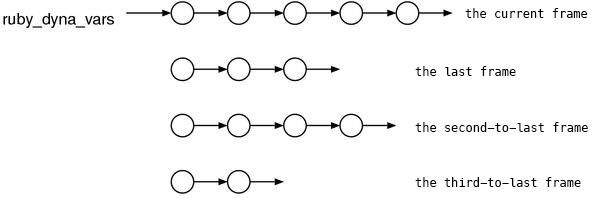
Fig.3: ruby_dyna_vars
ruby_class
ruby_class represents the current class to which a method is defined. Since
self will be that class when it’s a normal class definition statement,
ruby_class == self. But, when it is the top level or in the middle of
particular methods like eval and instance_eval, self != ruby_class is
possible.
The frame of ruby_class is a simple VALUE and there’s no particular frame
struct. Then, how could it be like a stack? Moreover, there were many structs
without the prev pointer, how could these form a stack? The answer is deferred
to the next section.
From now on, I’ll call this frame CLASS.
ruby_cref
ruby_cref represents the information of the nesting of a class.
I’ll call this frame CREF with the same way of naming as before.
Its struct is …
▼ ruby_cref
847 static NODE *ruby_cref = 0; (eval.c)
… surprisingly NODE. This is used just as a “defined struct which can be
pointed by a VALUE”. The node type is NODE_CREF and the assignments of its
members are shown below:
| Union Member | Macro To Access | Usage |
|---|---|---|
| u1.value | nd_clss | the outer class ( VALUE ) |
| u2 | – | – |
| u3.node | nd_next | preserve the previous CREF |
Even though the member name is nd_next, the value it actually has is the
“previous (prev)” CREF. Taking the following program as an example, I’ll
explain the actual appearance.
class A
class B
class C
nil # (A)
end
end
end
Fig.4 shows how ruby_cref is when evaluating the code (A).
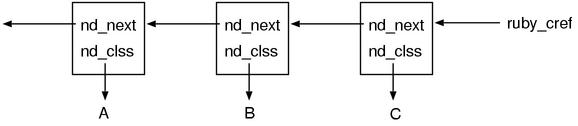
Fig.4: ruby_cref
However, illustrating this image everytime is tedious and its intention becomes unclear. Therefore, the same state as Fig.4 will be expressed in the following notation:
A ← B ← C
PUSH / POP Macros
For each stack frame struct, the macros to push and pop are available.
For instance, PUSH_FRAME and POP_FRAME for FRAME.
Because these will appear in a moment,
I’ll then explain the usage and content.
The other states
While they are not so important as the main stacks, the evaluator of ruby has
the several other states. This is a brief list of them. However, some of them
are not stacks. Actually, most of them are not.
| Variable Name | Type | Meaning |
|---|---|---|
scope_vmode |
int |
the default visibility when a method is defined |
ruby_in_eval |
int |
whether or not parsing after the evaluation is started |
ruby_current_node |
NODE* |
the file name and the line number of what currently being evaluated |
ruby_safe_level |
int |
$SAFE |
ruby_errinfo |
VALUE |
the exception currently being handled |
ruby_wrapper |
VALUE |
the wrapper module to isolate the environment |
Module Definition
The class statement and the module statement and the singleton class
definition statement, they are all implemented in similar ways.
Because seeing similar things continuously three times is not interesting, this time let’s
examine the module statement which has the least elements (thus, is simple).
First of all, what is the module statement? Conversely, what should happen is
the module statement ? Let’s try to list up several features:
- a new module object should be created
- the created module should be
self - it should have an independent local variable scope
- if you write a constant assignment, a constant should be defined on the module
- if you write a class variable assignment, a class variable should be defined on the module.
- if you write a
defstatement, a method should be defined on the module
What is the way to achieve these things? … is the point of this section. Now, let’s start to look at the codes.
Investigation
▼The Source Program
module M a = 1 end
▼Its Syntax Tree
NODE_MODULE
nd_cname = 9621 (M)
nd_body:
NODE_SCOPE
nd_rval = (null)
nd_tbl = 3 [ _ ~ a ]
nd_next:
NODE_LASGN
nd_cnt = 2
nd_value:
NODE_LIT
nd_lit = 1:Fixnum
nd_cname seems the module name. cname is probably either Const NAME or Class
NAME. I dumped several things and found that there’s always NODE_SCOPE in
nd_body. Since its member nd_tbl holds a local variable table and its name
is similar to struct SCOPE, it appears certain that this NODE_SCOPE
plays an important role to create a local variable scope.
NODE_MODULE
Let’s examine the handler of NODE_MODULE of rb_eval(). The parts that are
not close to the main line, such as ruby_raise() and error handling were cut
drastically. So far, there have been a lot of cutting works for 200 pages,
it has already became unnecessary to show the original code.
▼ rb_eval() − NODE_MODULE (simplified)
case NODE_MODULE:
{
VALUE module;
if (rb_const_defined_at(ruby_class, node->nd_cname)) {
/* just obtain the already created module */
module = rb_const_get(ruby_class, node->nd_cname);
}
else {
/* create a new module and set it into the constant */
module = rb_define_module_id(node->nd_cname);
rb_const_set(ruby_cbase, node->nd_cname, module);
rb_set_class_path(module,ruby_class,rb_id2name(node->nd_cname));
}
result = module_setup(module, node->nd_body);
}
break;
First, we’d like to make sure the module is nested and defined above (the module holded by) ruby_class.
We can understand it from the fact that it calls ruby_const_xxxx() on ruby_class.
Just once ruby_cbase appears, but it is usually identical to ruby_class,
so we can ignore it. Even if they are different, it rarely causes a problem.
The first half, it is branching by if because it needs to check if the
module has already been defined. This is because, in Ruby,
we can do “additional” definitions on the same one module any number of times.
module M def a # M#a is deifned end end module M # add a definition (not re-defining or overwriting) def b # M#b is defined end end
In this program, the two methods, a and b, will be defined on the module M.
In this case, on the second definition of M the module M was already set to
the constant, just obtaining and using it would be sufficient. If the constant
M does not exist yet, it means the first definition and the module is created
(by rb_define_module_id() )
Lastly, module_setup() is the function executing the body of a module
statement. Not only the module statements but the class statements and the
singleton class statements are executed by module_setup().
This is the reason why I said “all of these three type of statements are
similar things”.
For now, I’d like you to note that node->nd_body ( NODE_SCOPE ) is passed as
an argument.
module_setup
For the module and class and singleton class statements, module_setup()
executes their bodies. Finally, the Ruby stack manipulations will appear in
large amounts.
▼ module_setup()
3424 static VALUE
3425 module_setup(module, n)
3426 VALUE module;
3427 NODE *n;
3428 {
3429 NODE * volatile node = n;
3430 int state;
3431 struct FRAME frame;
3432 VALUE result; /* OK */
3433 TMP_PROTECT;
3434
3435 frame = *ruby_frame;
3436 frame.tmp = ruby_frame;
3437 ruby_frame = &frame;
3438
3439 PUSH_CLASS();
3440 ruby_class = module;
3441 PUSH_SCOPE();
3442 PUSH_VARS();
3443
/* (A)ruby_scope->local_vars initialization */
3444 if (node->nd_tbl) {
3445 VALUE *vars = TMP_ALLOC(node->nd_tbl[0]+1);
3446 *vars++ = (VALUE)node;
3447 ruby_scope->local_vars = vars;
3448 rb_mem_clear(ruby_scope->local_vars, node->nd_tbl[0]);
3449 ruby_scope->local_tbl = node->nd_tbl;
3450 }
3451 else {
3452 ruby_scope->local_vars = 0;
3453 ruby_scope->local_tbl = 0;
3454 }
3455
3456 PUSH_CREF(module);
3457 ruby_frame->cbase = (VALUE)ruby_cref;
3458 PUSH_TAG(PROT_NONE);
3459 if ((state = EXEC_TAG()) == 0) {
3460 if (trace_func) {
3461 call_trace_func("class", ruby_current_node, ruby_class,
3462 ruby_frame->last_func,
3463 ruby_frame->last_class);
3464 }
3465 result = rb_eval(ruby_class, node->nd_next);
3466 }
3467 POP_TAG();
3468 POP_CREF();
3469 POP_VARS();
3470 POP_SCOPE();
3471 POP_CLASS();
3472
3473 ruby_frame = frame.tmp;
3474 if (trace_func) {
3475 call_trace_func("end", ruby_last_node, 0,
3476 ruby_frame->last_func, ruby_frame->last_class);
3477 }
3478 if (state) JUMP_TAG(state);
3479
3480 return result;
3481 }
(eval.c)
This is too big to read all in one gulp. Let’s cut the parts that seems unnecessary.
First, the parts around trace_func can be deleted unconditionally.
We can see the idioms related to tags. Let’s simplify them by expressing with the Ruby’s ensure.
Immediately after the start of the function, the argument n is purposefully
assigned to the local variable node, but volatile is attached to node and
it would never be assigned after that, thus this is to prevent from being
garbage collected. If we assume that the argument was node from the beginning,
it would not change the meaning.
In the first half of the function, there’s the part manipulating ruby_frame
complicatedly. It is obviously paired up with the part ruby_frame = frame.tmp
in the last half. We’ll focus on this part later, but for the time being this
can be considered as push pop of ruby_frame.
Plus, it seems that the code (A) can be, as commented, summarized as the
initialization of ruby_scope->local_vars. This will be discussed later.
Consequently, it could be summarized as follows:
▼ module_setup (simplified)
static VALUE
module_setup(module, node)
VALUE module;
NODE *node;
{
struct FRAME frame;
VALUE result;
push FRAME
PUSH_CLASS();
ruby_class = module;
PUSH_SCOPE();
PUSH_VARS();
ruby_scope->local_vars initializaion
PUSH_CREF(module);
ruby_frame->cbase = (VALUE)ruby_cref;
begin
result = rb_eval(ruby_class, node->nd_next);
ensure
POP_TAG();
POP_CREF();
POP_VARS();
POP_SCOPE();
POP_CLASS();
pop FRAME
end
return result;
}
It does rb_eval() with node->nd_next,
so it’s certain that this is the code of the module body.
The problems are about the others. There are 5 points to see.
- Things occur on
PUSH_SCOPE() PUSH_VARS() - How the local variable space is allocated
- The effect of
PUSH_CLASS - The relationship between
ruby_crefandruby_frame->cbase - What is done by manipulating
ruby_frame
Let’s investigate them in order.
Creating a local variable scope
PUSH_SCOPE pushes a local variable space and PUSH_VARS() pushes a block
local variable space, thus a new local variable scope is created by these two.
Let’s examine the contents of these macros and what is done.
▼ PUSH_SCOPE() POP_SCOPE()
852 #define PUSH_SCOPE() do { \
853 volatile int _vmode = scope_vmode; \
854 struct SCOPE * volatile _old; \
855 NEWOBJ(_scope, struct SCOPE); \
856 OBJSETUP(_scope, 0, T_SCOPE); \
857 _scope->local_tbl = 0; \
858 _scope->local_vars = 0; \
859 _scope->flags = 0; \
860 _old = ruby_scope; \
861 ruby_scope = _scope; \
862 scope_vmode = SCOPE_PUBLIC
869 #define POP_SCOPE() \
870 if (ruby_scope->flags & SCOPE_DONT_RECYCLE) { \
871 if (_old) scope_dup(_old); \
872 } \
873 if (!(ruby_scope->flags & SCOPE_MALLOC)) { \
874 ruby_scope->local_vars = 0; \
875 ruby_scope->local_tbl = 0; \
876 if (!(ruby_scope->flags & SCOPE_DONT_RECYCLE) && \
877 ruby_scope != top_scope) { \
878 rb_gc_force_recycle((VALUE)ruby_scope); \
879 } \
880 } \
881 ruby_scope->flags |= SCOPE_NOSTACK; \
882 ruby_scope = _old; \
883 scope_vmode = _vmode; \
884 } while (0)
(eval.c)
As the same as tags, SCOPE s also create a stack by being synchronized with the
machine stack. What differentiate slightly is that the spaces of the stack
frames are allocated in the heap, the machine stack is used in order to create
the stack structure (Fig.5.).
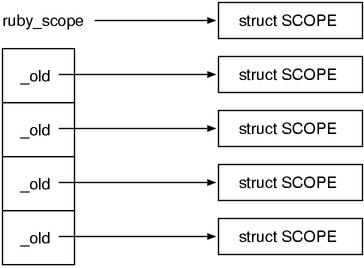
Fig.5. The machine stack and the SCOPE Stack
Additionally, the flags like SCOPE_ something repeatedly appearing in the
macros are not able to be explained until I finish to talk all about
in what form each stack frame is remembered and about blocks.
Thus, these will be discussed in Chapter 16: Blocks all at once.
Allocating the local variable space
As I mentioned many times, the local variable scope is represented by struct SCOPE.
But struct SCOPE is literally a “scope” and it does not have the real body
to store local variables. To put it more precisely, it has the pointer to a
space but there’s still no array at the place where the one points to. The
following part of module_setup prepares the array.
▼The preparation of the local variable slots
3444 if (node->nd_tbl) {
3445 VALUE *vars = TMP_ALLOC(node->nd_tbl[0]+1);
3446 *vars++ = (VALUE)node;
3447 ruby_scope->local_vars = vars;
3448 rb_mem_clear(ruby_scope->local_vars, node->nd_tbl[0]);
3449 ruby_scope->local_tbl = node->nd_tbl;
3450 }
3451 else {
3452 ruby_scope->local_vars = 0;
3453 ruby_scope->local_tbl = 0;
3454 }
(eval.c)
The TMP_ALLOC() at the beginning will be described in the next section. If I
put it shortly, it is “alloca that is assured to allocate on the stack
(therefore, we do not need to worry about GC)”.
node->nd_tbl holds in fact the local variable name table that has appeared
in Chapter 12: Syntax tree construction. It means that nd_tbl[0] contains the table size and the rest is
an array of ID. This table is directly preserved to local_tbl of SCOPE
and local_vars is allocated to store the local variable values.
Because they are confusing, it’s a good thing writing some comments such as
“This is the variable name”, “this is the value”.
The one with tbl is for the names.

Fig.6. ruby_scope->local_vars
Where is this node used?
I examined the all local_vars members but could not find the access to index
-1 in eval.c. Expanding the range of files to investigate, I found the
access in gc.c.
▼ rb_gc_mark_children() — T_SCOPE
815 case T_SCOPE:
816 if (obj->as.scope.local_vars &&
(obj->as.scope.flags & SCOPE_MALLOC)) {
817 int n = obj->as.scope.local_tbl[0]+1;
818 VALUE *vars = &obj->as.scope.local_vars[-1];
819
820 while (n--) {
821 rb_gc_mark(*vars);
822 vars++;
823 }
824 }
825 break;
(gc.c)
Apparently, this is a mechanism to protect node from GC.
But why is it necessary to to mark it here?
node is purposefully store into the volatile local variable, so
it would not be garbage-collected during the execution of module_setup().
Honestly speaking, I was thinking it might merely be a mistake for a while but it turned out it’s actually very important. The issue is this at the next line of the next line:
▼ ruby_scope->local_tbl
3449 ruby_scope->local_tbl = node->nd_tbl; (eval.c)
The local variable name table prepared by the parser is directly used. When is
this table freed? It’s the time when the node become not to be referred from
anywhere. Then, when should node be freed? It’s the time after the SCOPE
assigned on this line will disappear completely. Then, when is that?
SCOPE sometimes persists longer than the statement that causes the creation
of it. As it will be discussed at Chapter 16: Blocks,
if a Proc object is created, it refers SCOPE.
Thus, If module_setup() has finished, the SCOPE created there is not
necessarily be what is no longer used. That’s why it’s not sufficient that
node is only referred from (the stack frame of) module_setup().
It must be referred “directly” from SCOPE.
On the other hand, the volatile node of the local variable cannot be removed.
Without it, node is floating on air until it will be assigned to local_vars.
However then, local_vars of SCOPE is not safe, isn’t it?
TMP_ALLOC() is, as I mentioned, the allocation on the stack, it becomes
invalid at the time module_setup() ends. This is in fact, at the moment when
Proc is created, the allocation method is abruptly switched to malloc().
Details will be described in Chapter 16: Blocks.
Lastly, rb_mem_clear() seems zero-filling but actually it is Qnil -filling to
an array of VALUE ( array.c ). By this, all defined local variables are
initialized as nil.
TMP_ALLOC
Next, let’s read TMP_ALLOC that allocates the local variable space.
This macro is actually paired with TMP_PROTECT existing silently at the
beginning of module_setup(). Its typical usage is this:
VALUE *ptr; TMP_PROTECT; ptr = TMP_ALLOC(size);
The reason why TMP_PROTECT is in the place for the local variable definitions
is that … Let’s see its definition.
▼ TMP_ALLOC()
1769 #ifdef C_ALLOCA 1770 # define TMP_PROTECT NODE * volatile tmp__protect_tmp=0 1771 # define TMP_ALLOC(n) \ 1772 (tmp__protect_tmp = rb_node_newnode(NODE_ALLOCA, \ 1773 ALLOC_N(VALUE,n), tmp__protect_tmp, n), \ 1774 (void*)tmp__protect_tmp->nd_head) 1775 #else 1776 # define TMP_PROTECT typedef int foobazzz 1777 # define TMP_ALLOC(n) ALLOCA_N(VALUE,n) 1778 #endif (eval.c)
… it is because it defines a local variable.
As described in Chapter 5: Garbage collection, in the environment of #ifdef C_ALLOCA (that is,
the native alloca() does not exist) malloca() is used to emulate alloca().
However, the arguments of a method are obviously VALUE s and
the GC could not find a VALUE if it is stored in the heap.
Therefore, it is enforced that GC can find it through NODE.
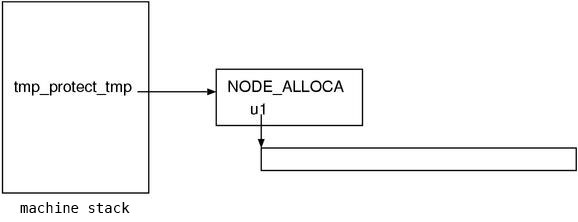
Fig.7. anchor the space to the stack through NODE
On the contrary, in the environment with the true alloca(), we can naturally
use alloca() and there’s no need to use TMP_PROTECT. Thus, a harmless
statement is arbitrarily written.
By the way, why do they want to use alloca() very much by all means.
It’s merely because " alloca() is faster than malloc()", they said.
One can think that it’s not so worth to care about such tiny difference,
but because the core of the evaluator is the biggest bottleneck of ruby,
… the same as above.
Changing the place to define methods on.
The value of the stack ruby_class is the place to define a method on at the
time. Conversely, if one push a value to ruby_class, it changes the class to
define a method on. This is exactly what is necessary for a class statement.
Therefore, It’s also necessary to do PUSH_CLASS() in module_setup().
Here is the code for it:
PUSH_CLASS();
ruby_class = module;
:
:
POP_CLASS();
Why is there the assignment to ruby_class after doing PUSH_CLASS().
We can understand it unexpectedly easily by looking at the definition.
▼ PUSH_CLASS() POP_CLASS()
841 #define PUSH_CLASS() do { \
842 VALUE _class = ruby_class
844 #define POP_CLASS() ruby_class = _class; \
845 } while (0)
(eval.c)
Because ruby_class is not modified even though PUSH_CLASS is done,
it is not actually pushed until setting by hand.
Thus, these two are closer to “save and restore” rather than “push and pop”.
You might think that it can be a cleaner macro if passing a class as the
argument of PUSH_CLASS() … It’s absolutely true, but because there are some
places we cannot obtain the class before pushing, it is in this way.
Nesting Classes
ruby_cref represents the class nesting information at runtime. Therefore, it’s
naturally predicted that ruby_cref will be pushed on the module statements or
on the class statements.
In module_setup(), it is pushed as follows:
PUSH_CREF(module); ruby_frame->cbase = (VALUE)ruby_cref; : : POP_CREF();
Here, module is the module being defined.
Let’s also see the definitions of PUSH_CREF() and POP_CREF().
▼ PUSH_CREF() POP_CREF()
849 #define PUSH_CREF(c) \
ruby_cref = rb_node_newnode(NODE_CREF,(c),0,ruby_cref)
850 #define POP_CREF() ruby_cref = ruby_cref->nd_next
(eval.c)
Unlike PUSH_SCOPE or something, there are not any complicated techniques and
it’s very easy to deal with.
It’s also not good if there’s completely not any such thing.
The problem remains unsolved is what is the meaning of ruby_frame->cbase.
It is the information to refer a class variable or a constant from the current FRAME.
Details will be discussed in the last section of this chapter.
Replacing frames
Lastly, let’s focus on the manipulation of ruby_frame. The first thing is its
definition:
struct FRAME frame;
It is not a pointer. This means that the entire FRAME is allocated on the stack.
Both the management structure of the Ruby stack and the local variable
space are on the stack, but in the case of FRAME the entire struct is stored
on the stack. The extreme consumption of the machine stack by ruby is the
fruit of these “small techniques” piling up.
Then next, let’s look at where doing several things with frame.
frame = *ruby_frame; /* copy the entire struct */
frame.tmp = ruby_frame; /* protect the original FRAME from GC */
ruby_frame = &frame; /* replace ruby_frame */
:
:
ruby_frame = frame.tmp; /* restore */
That is, ruby_frame seems temporarily replaced (not pushing).
Why is it doing such thing?
I described that FRAME is “pushed on method calls”, but to be more precise,
it is the stack frame to represent “the main environment to execute a Ruby program”.
You can infer it from, for instance, ruby_frame->cbase which appeared previously.
last_func which is “the last called method name” also suggests it.
Then, why is FRAME not straightforwardly pushed?
It is because this is the place where it is not allowed to push FRAME.
FRAME is wanted to be pushed, but if FRAME is pushed,
it will appear in the backtraces of the program when an exception occurs.
The backtraces are things displayed like followings:
% ruby t.rb
t.rb:11:in `c': some error occured (ArgumentError)
from t.rb:7:in `b'
from t.rb:3:in `a'
from t.rb:14
But the module statements and the class statements are not method calls, so it is not desirable to appear in this. That’s why it is “replaced” instead of “pushed”.
The method definition
As the next topic of the module definitions, let’s look at the method definitions.
Investigation
▼The Source Program
def m(a, b, c) nil end
▼Its Syntax Tree
NODE_DEFN
nd_mid = 9617 (m)
nd_noex = 2 (NOEX_PRIVATE)
nd_defn:
NODE_SCOPE
nd_rval = (null)
nd_tbl = 5 [ _ ~ a b c ]
nd_next:
NODE_ARGS
nd_cnt = 3
nd_rest = -1
nd_opt = (null)
NODE_NIL
I dumped several things and found that there’s always NODE_SCOPE in nd_defn.
NODE_SCOPE is, as we’ve seen at the module statements,
the node to store the information to push a local variable scope.
NODE_DEFN
Subsequently, we will examine the corresponding code of rb_eval(). This part
contains a lot of error handlings and tedious, they are all omitted again.
The way of omitting is as usual, deleting the every parts to directly or
indirectly call rb_raise() rb_warn() rb_warning().
▼ rb_eval() − NODE_DEFN (simplified)
NODE *defn;
int noex;
if (SCOPE_TEST(SCOPE_PRIVATE) || node->nd_mid == init) {
noex = NOEX_PRIVATE; (A)
}
else if (SCOPE_TEST(SCOPE_PROTECTED)) {
noex = NOEX_PROTECTED; (B)
}
else if (ruby_class == rb_cObject) {
noex = node->nd_noex; (C)
}
else {
noex = NOEX_PUBLIC; (D)
}
defn = copy_node_scope(node->nd_defn, ruby_cref);
rb_add_method(ruby_class, node->nd_mid, defn, noex);
result = Qnil;
In the first half, there are the words like private or protected, so it is
probably related to visibility. noex, which is used as the names of flags,
seems NOde EXposure. Let’s examine the if statements in order.
(A) SCOPE_TEST() is a macro to check if there’s an argument flag in
scope_vmode. Therefore, the first half of this conditional statement means
“is it a private scope?”.
The last half means “it’s private if this is defining initialize”.
The method initialize to initialize an object will unquestionably become private.
(B) It is protected if the scope is protected (not surprisingly).
My feeling is that there’re few cases protected is required in Ruby.
(C) This is a bug. I found this just before the submission of this book,
so I couldn’t fix this beforehand.
In the latest code this part is probably already removed.
The original intention is to enforce the methods defined at top level to be private.
(D) If it is not any of the above conditions, it is public.
Actually, there’s not a thing to worth to care about until here. The important part is the next two lines.
defn = copy_node_scope(node->nd_defn, ruby_cref); rb_add_method(ruby_class, node->nd_mid, defn, noex);
copy_node_scope() is a function to copy (only) NODE_SCOPE attached to the
top of the method body. It is important that ruby_cref is passed …
but details will be described soon.
After copying, the definition is finished by adding it by rb_add_method().
The place to define on is of course ruby_class.
copy_node_scope()
copy_node_scope() is called only from the two places: the method definition
( NODE_DEFN ) and the singleton method definition ( NODE_DEFS ) in rb_eval().
Therefore, looking at these two is sufficient to detect how it is used. Plus,
the usages at these two places are almost the same.
▼ copy_node_scope()
1752 static NODE*
1753 copy_node_scope(node, rval)
1754 NODE *node;
1755 VALUE rval;
1756 {
1757 NODE *copy = rb_node_newnode(NODE_SCOPE,0,rval,node->nd_next);
1758
1759 if (node->nd_tbl) {
1760 copy->nd_tbl = ALLOC_N(ID, node->nd_tbl[0]+1);
1761 MEMCPY(copy->nd_tbl, node->nd_tbl, ID, node->nd_tbl[0]+1);
1762 }
1763 else {
1764 copy->nd_tbl = 0;
1765 }
1766 return copy;
1767 }
(eval.c)
I mentioned that the argument rval is the information of the class nesting
( ruby_cref ) of when the method is defined. Apparently, it is rval because it
will be set to nd_rval.
In the main if statement copies nd_tbl of NODE_SCOPE.
It is a local variable name table in other words. The +1 at ALLOC_N is to
additionally allocate the space for nd_tbl[0]. As we’ve seen in Part 2,
nd_tbl[0] holds the local variables count, that was “the actual length of
nd_tbl – 1”.
To summarize, copy_node_scope() makes a copy of the NODE_SCOPE which is the
header of the method body. However, nd_rval is additionally set and it is the
ruby_cref (the class nesting information) of when the class is defined. This
information will be used later when referring constants or class variables.
rb_add_method()
The next thing is rb_add_method() that is the function to register a method entry.
▼ rb_add_method()
237 void
238 rb_add_method(klass, mid, node, noex)
239 VALUE klass;
240 ID mid;
241 NODE *node;
242 int noex;
243 {
244 NODE *body;
245
246 if (NIL_P(klass)) klass = rb_cObject;
247 if (ruby_safe_level >= 4 &&
(klass == rb_cObject || !OBJ_TAINTED(klass))) {
248 rb_raise(rb_eSecurityError, "Insecure: can't define method");
249 }
250 if (OBJ_FROZEN(klass)) rb_error_frozen("class/module");
251 rb_clear_cache_by_id(mid);
252 body = NEW_METHOD(node, noex);
253 st_insert(RCLASS(klass)->m_tbl, mid, body);
254 }
(eval.c)
NEW_METHOD() is a macro to create NODE.
rb_clear_cache_by_id() is a function to manipulate the method cache.
This will be explained in the next chapter “Method”.
Let’s look at the syntax tree which is eventually stored in m_tbl of a class.
I prepared nodedump-method for this kind of purposes.
(nodedump-method : comes with nodedump. nodedump is tools/nodedump.tar.gz of the attached CD-ROM)
% ruby -e '
class C
def m(a)
puts "ok"
end
end
require "nodedump-method"
NodeDump.dump C, :m # dump the method m of the class C
'
NODE_METHOD
nd_noex = 0 (NOEX_PUBLIC)
nd_cnt = 0
nd_body:
NODE_SCOPE
nd_rval = Object <- C
nd_tbl = 3 [ _ ~ a ]
nd_next:
NODE_ARGS
nd_cnt = 1
nd_rest = -1
nd_opt = (null)
U牙S頏著
** unhandled**
There are NODE_METHOD at the top
and NODE_SCOPE previously copied by copy_node_scope() at the next.
These probably represent the header of a method.
I dumped several things and there’s not any NODE_SCOPE with the methods defined in C,
thus it seems to indicate that the method is defined at Ruby level.
Additionally, at nd_tbl of NODE_SCOPE the parameter variable name ( a ) appears.
I mentioned that the parameter variables are equivalent to the local variables,
and this briefly implies it.
I’ll omit the explanation about NODE_ARGS here
because it will be described at the next chapter “Method”.
Lastly, the nd_cnt of the NODE_METHOD, it’s not so necessary to care about
this time. It is used when having to do with alias.
Assignment and Reference
Come to think of it, most of the stacks are used to realize a variety of variables. We have learned to push various stacks, this time let’s examine the code to reference variables.
Local variable
The all necessary information to assign or refer local variables has appeared, so you are probably able to predict. There are the following two points:
- local variable scope is an array which is pointed by
ruby_scope->local_vars - the correspondence between each local variable name and each array index has already resolved at the parser level.
Therefore, the code for the local variable reference node NODE_LVAR is as
follows:
▼ rb_eval() − NODE_LVAR
2975 case NODE_LVAR:
2976 if (ruby_scope->local_vars == 0) {
2977 rb_bug("unexpected local variable");
2978 }
2979 result = ruby_scope->local_vars[node->nd_cnt];
2980 break;
(eval.c)
It goes without saying but node->nd_cnt is the value that local_cnt() of the
parser returns.
Constant
Complete Specification
In Chapter 6: Variables and constants,
I talked about in what form constants are stored and API.
Constants are belong to classes and inherited as the same as methods.
As for their actual appearances, they are registered to iv_tbl of
struct RClass with instance variables and class variables.
The searching path of a constant is firstly the outer class, secondly the
superclass, however, rb_const_get() only searches the superclass. Why?
To answer this question, I need to reveal the last specification of constants.
Take a look at the following code:
class A
C = 5
def A.new
puts C
super
end
end
A.new is a singleton method of A, so its class is the singleton class (A).
If it is interpreted by following the rule,
it cannot obtain the constant C which is belongs to A.
But because it is written so close, to become to want refer the constant C
is human nature. Therefore, such reference is possible in Ruby.
It can be said that this specification reflects the characteristic of Ruby
“The emphasis is on the appearance of the source code”.
If I generalize this rule, when referring a constant from inside of a method,
by setting the place which the method definition is “written” as the start
point, it refers the constant of the outer class.
And, “the class of where the method is written” depends on its context,
thus it could not be handled without the information from both the parser and
the evaluator. This is why rb_cost_get() did not have the searching path of
the outer class.
cbase
Then, let’s look at the code to refer constants including the outer class.
The ordinary constant references to which :: is not attached, become
NODE_CONST in the syntax tree. The corresponding code in rb_eval() is …
▼ rb_eval() − NODE_CONST
2994 case NODE_CONST: 2995 result = ev_const_get(RNODE(ruby_frame->cbase), node->nd_vid, self); 2996 break; (eval.c)
First, nd_vid appears to be Variable ID and it probably means a constant name.
And, ruby_frame->cbase is “the class where the method definition is written”.
The value will be set when invoking the method, thus the code to set has not appeared yet.
And the place where the value to be set comes from is the nd_rval
that has appeared in copy_node_scope() of the method definition.
I’d like you to go back a little and check that the member holds the
ruby_cref of when the method is defined.
This means, first, the ruby_cref link is built when defining a class or a module.
Assume that the just defined class is C (Fig.81),
Defining the method m (this is probably C#m ) here,
then the current ruby_cref is memorized by the method entry (Fig.82).
After that, when the class statement finished the ruby_cref would start to
point another node, but node->nd_rval naturally continues to point to the
same thing. (Fig.83)
Then, when invoking the method C#m, get node->nd_rval
and insert into the just pushed ruby_frame->cbase (Fig.84)
… This is the mechanism. Complicated.
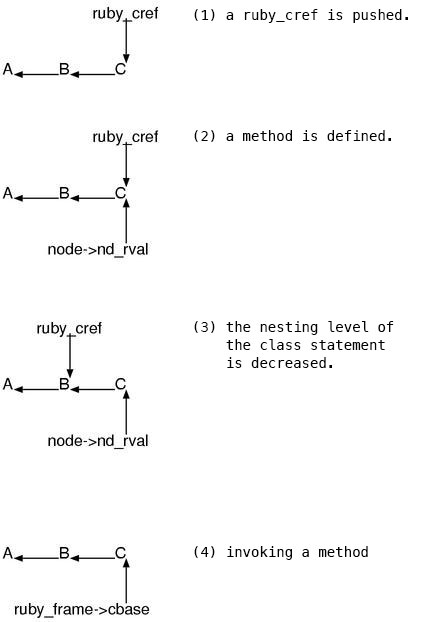
Fig 8. CREF Trasfer
ev_const_get()
Now, let’s go back to the code of NODE_CONST.
Since only ev_const_get() is left, we’ll look at it.
▼ ev_const_get()
1550 static VALUE
1551 ev_const_get(cref, id, self)
1552 NODE *cref;
1553 ID id;
1554 VALUE self;
1555 {
1556 NODE *cbase = cref;
1557 VALUE result;
1558
1559 while (cbase && cbase->nd_next) {
1560 VALUE klass = cbase->nd_clss;
1561
1562 if (NIL_P(klass)) return rb_const_get(CLASS_OF(self), id);
1563 if (RCLASS(klass)->iv_tbl &&
st_lookup(RCLASS(klass)->iv_tbl, id, &result)) {
1564 return result;
1565 }
1566 cbase = cbase->nd_next;
1567 }
1568 return rb_const_get(cref->nd_clss, id);
1569 }
(eval.c)
(( According to the errata, the description of ev_const_get() was wrong.
I omit this part for now. ))
Class variable
What class variables refer to is also ruby_cref. Needless to say,
unlike the constants which search over the outer classes one after another,
it uses only the first element.
Let’s look at the code of NODE_CVAR which is the node to refer to a class
variable.
What is the cvar_cbase() ? As cbase is attached,
it is probably related to ruby_frame->cbase, but how do they differ?
Let’s look at it.
▼ cvar_cbase()
1571 static VALUE
1572 cvar_cbase()
1573 {
1574 NODE *cref = RNODE(ruby_frame->cbase);
1575
1576 while (cref && cref->nd_next &&
FL_TEST(cref->nd_clss, FL_SINGLETON)) {
1577 cref = cref->nd_next;
1578 if (!cref->nd_next) {
1579 rb_warn("class variable access from toplevel singleton method");
1580 }
1581 }
1582 return cref->nd_clss;
1583 }
(eval.c)
It traverses cbase up to the class that is not the singleton class, it
seems. This feature is added to counter the following kind of code:
class C class C
@@cvar = 1 @@cvar = 1
class << C def C.m
def m @@cvar
@@cvar end
end def C.m2
def m2 @@cvar + @@cvar
@@cvar + @@cvar end
end end
end
end
Both the left and right code ends up defining the same method, but if you write in the way of the right side it is tedious to write the class name repeatedly as the number of methods increases. Therefore, when defining multiple singleton methods, many people choose to write in the left side way of using the singleton class definition statement to bundle.
However, these two differs in the value of ruby_cref. The one using the
singleton class definition is ruby_cref=(C) and the other one defining
singleton methods separately is ruby_cref=C. This may cause to differ in the
places where class variables refer to, so this is not convenient.
Therefore, assuming it’s rare case to define class variables on singleton classes, it skips over singleton classes. This reflects again that the emphasis is more on the usability rather than the consistency.
And, when the case is a constant reference,
since it searches all of the outer classes,
C is included in the search path in either way, so there’s no problem.
Plus, as for an assignment, since it couldn’t be written inside methods in the
first place, it is also not related.
Multiple Assignment
If someone asked “where is the most complicated specification of Ruby?”, I would instantly answer that it is multiple assignment. It is even impossible to understand the big picture of multiple assignment, I have an account of why I think so. In short, the specification of the multiple assignment is defined without even a subtle intention to construct so that the whole specification is well-organized. The basis of the specification is always “the behavior which seems convenient in several typical use cases”. This can be said about the entire Ruby, but particularly about the multiple assignment.
Then, how could we avoid being lost in the jungle of codes. This is similar to reading the stateful scanner and it is not seeing the whole picture. There’s no whole picture in the first place, we could not see it. Cutting the code into blocks like, this code is written for this specification, that code is written for that specification, … understanding the correspondences one by one in such manner is the only way.
But this book is to understand the overall structure of ruby and is not
“Advanced Ruby Programming”. Thus, dealing with very tiny things is not fruitful.
So here, we only think about the basic structure of multiple assignment
and the very simple “multiple-to-multiple” case.
First, following the standard, let’s start with the syntax tree.
▼The Source Program
a, b = 7, 8
▼Its Syntax Tree
NODE_MASGN
nd_head:
NODE_ARRAY [
0:
NODE_LASGN
nd_cnt = 2
nd_value:
1:
NODE_LASGN
nd_cnt = 3
nd_value:
]
nd_value:
NODE_REXPAND
nd_head:
NODE_ARRAY [
0:
NODE_LIT
nd_lit = 7:Fixnum
1:
NODE_LIT
nd_lit = 8:Fixnum
]
Both the left-hand and right-hand sides are the lists of NODE_ARRAY,
there’s additionally NODE_REXPAND in the right side. REXPAND may be “Right
value EXPAND”. We are curious about what this node is doing. Let’s see.
▼ rb_eval() − NODE_REXPAND
2575 case NODE_REXPAND: 2576 result = avalue_to_svalue(rb_eval(self, node->nd_head)); 2577 break; (eval.c)
You can ignore avalue_to_svalue().
NODE_ARRAY is evaluated by rb_eval(), (because it is the node of the array
literal), it is turned into a Ruby array and returned back.
So, before the left-hand side is handled, all in the right-hand side are
evaluated. This enables even the following code:
a, b = b, a # swap variables in oneline
Let’s look at NODE_MASGN in the left-hand side.
▼ rb_eval() − NODE_MASGN
2923 case NODE_MASGN: 2924 result = massign(self, node, rb_eval(self, node->nd_value),0); 2925 break; (eval.c)
Here is only the evaluation of the right-hand side, the rests are delegated to
massign().
massign()
▼ massi ……
3917 static VALUE
3918 massign(self, node, val, pcall)
3919 VALUE self;
3920 NODE *node;
3921 VALUE val;
3922 int pcall;
3923 {
(eval.c)
I’m sorry this is halfway, but I’d like you to stop and pay attention to the
4th argument. pcall is Proc CALL, this indicates whether or not the
function is used to call Proc object. Between Proc calls and the others
there’s a little difference in the strictness of the check of the multiple
assignments, so a flag is received to check.
Obviously, the value is decided to be either 0 or 1.
Then, I’d like you to look at the previous code calling massign(), it was
pcall=0. Therefore, we probably don’t mind if assuming it is pcall=0 for the
time being and extracting the variables. That is, when there’s an argument like
pcall which is slightly changing the behavior, we always need to consider the
two patterns of scenarios, so it is really cumbersome. If there’s only one
actual function massign(), to think as if there were two functions, pcall=0
and pcall=1, is way simpler to read.
When writing a program we must avoid duplications as much as possible, but this principle is unrelated if it is when reading. If patterns are limited, copying it and letting it to be redundant is rather the right approach. There are wordings “optimize for speed” “optimize for the code size”, in this case we’ll “optimize for readability”.
So, assuming it is pcall=0 and cutting the codes as much as possible and the
final appearance is shown as follows:
▼ massign() (simplified)
static VALUE
massign(self, node, val /* , pcall=0 */)
VALUE self;
NODE *node;
VALUE val;
{
NODE *list;
long i = 0, len;
val = svalue_to_mvalue(val);
len = RARRAY(val)->len;
list = node->nd_head;
/* (A) */
for (i=0; list && i<len; i++) {
assign(self, list->nd_head, RARRAY(val)->ptr[i], pcall);
list = list->nd_next;
}
/* (B) */
if (node->nd_args) {
if (node->nd_args == (NODE*)-1) {
/* no check for mere `*' */
}
else if (!list && i<len) {
assign(self, node->nd_args,
rb_ary_new4(len-i, RARRAY(val)->ptr+i), pcall);
}
else {
assign(self, node->nd_args, rb_ary_new2(0), pcall);
}
}
/* (C) */
while (list) {
i++;
assign(self, list->nd_head, Qnil, pcall);
list = list->nd_next;
}
return val;
}
val is the right-hand side value. And there’s the suspicious conversion called
svalue_to_mvalue(), since mvalue_to_svalue() appeared previously and
svalue_to_mvalue() in this time, so you can infer “it must be getting back”.
((errata: it was avalue_to_svalue() in the previous case.
Therefore, it’s hard to infer “getting back”, but you can ignore them anyway.))
Thus, the both are deleted. In the next line, since it uses RARRAY(),
you can infer that the right-hand side value is an Array of Ruby.
Meanwhile, the left-hand side is node->nd_head, so it is the value assigned to
the local variable list. This list is also a node ( NODE_ARRAY ).
We’ll look at the code by clause.
(A) assign is, as the name suggests, a function to perform an one-to-one
assignment. Since the left-hand side is expressed by a node,
if it is, for instance, NODE_IASGN (an assignment to an instance variable),
it assigns with rb_ivar_set().
So, what it is doing here is adjusting to either list and val which is
shorter and doing one-to-one assignments. (Fig.9)
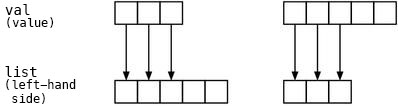
Fig.9. assign when corresponded
(B) if there are remainders on the right-hand side, turn them into a Ruby
array and assign it into (the left-hand side expressed by) the node->nd_args.
(C) if there are remainders on the left-hand side, assign nil to all of them.
By the way, the procedure which is assuming pcall=0 then cutting out is very
similar to the data flow analytics / constant foldings used on the optimization
phase of compilers.
Therefore, we can probably automate it to some extent.